这是一篇关于 Baidu Research 凤巢团队的论文 Mobius 阅读笔记&想法,是百度凤巢团队发表在 KDD 2019 上的一篇广告检索相关的论文,最近调研排序和召回联动方法时觉得比较有意思,除了模型上的创新,其配套的数据采样方法也十分值得学习。
摘要
百度搜索是大陆地区的第一搜索引擎,服务上亿的用户,为了在计算资源有限的情况下构建一个低延迟的高效广告推荐引擎,百度之前的方案是经典的漏斗型召回-排序框架,召回层主要目标是找出与用户 query 语义相关的候选广告集,排序层则更多考虑效率指标例如 CPM(Cost per Mille)、ROI(Return on Investment) 等,但召回和排序层这种割裂的优化目标会限制商业收入。
Mobius 的提出旨在解决上述问题,这也是百度首次尝试除了相关性之外,在召回的优化目标中添加效率指标(CPM),具体的做法是直接预测 query-ad pair 的点击率指标,在这个过程中还运用了主动学习(avtive learning)来解决离线训练中,召回层点击历史不足的问题,最终可以达到一个较好的相关性和商业指标的 trade off。
引言
传统的广告推荐系统,如下图 1 所示,一般是漏斗型的框架,主要是召回-粗排-精排结构,召回层主要目标是考虑用户 query 和候选集的语义相关性,为后续的排序模型提供打分集;排序一般包含两层一般称为粗排和精排,主要考虑 CPM 等效率指标,其中粗排的存在主要是解决精排模型的性能效率问题,一般设计为双塔结构使得粗排模型可以在保有不俗指标的情况下提升其处理能力(数以千计);精排模型则从粗排模型提供的数以百计的广告中进行排序得到最终的展示排序结果。
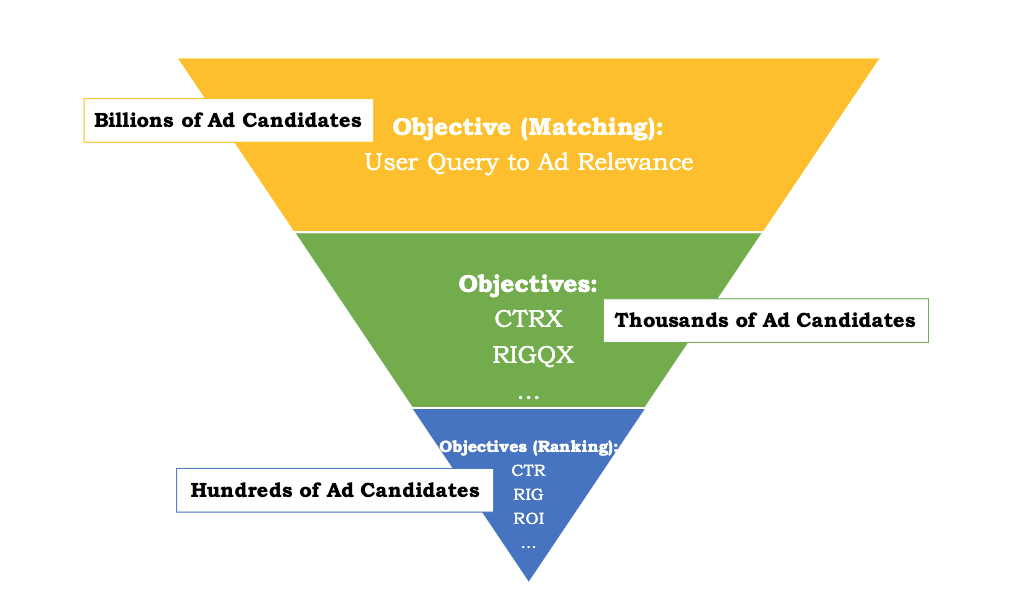
Fig. 1. 传统的三层漏斗型广告推荐框架,根据用户的 query ,可以高效的从亿级候选集中检索出相关并且具有 high-CPM 的广告. (Image source: M Fan et al.)
然而,从上面的描述我们不难发现,召回层和后序的排序层的目标是割裂的。并且,最令人失望的是,排序模型的排序结果往往会告诉我们,许多召回层提供的相关广告并不具有 high-CPM,也不会被展示出来。在这种挑战下,Mobius 的提出可以称作为下一代广告推荐引擎,旨在维持低响应延迟、计算资源的受限,并且只会造成很小的用户负面体验的情况下,统一不同阶段的的学习目标,包括广告相关性和许多其他业务效率指标。
为了完成这个目标,Mobius 首次提出在召回层考虑 CPM 等效率指标,这意味着在召回层,模型就可以完成相关性匹配和快速预测 query-ad pair 的点击率,此时如下图 2 所示,相当于召回和排序统一为一层,相当于把原来的独立的目标函数整合为公式 1:
\[\begin{aligned} &O_{\text {Mobius}-V 1}=\max \sum_{i=1}^{n} \mathrm{CTR}\left(user_{i}, query_{i}, ad_{i}\right) \times B i d_{i}\\ &\text {s.t. } \frac{1}{n} \sum_{i=1}^{n} \text { Relevance }\left(q u e r y_{i}, a d_{i}\right) \geq t h r e s h o l d \end{aligned} \tag{1}\]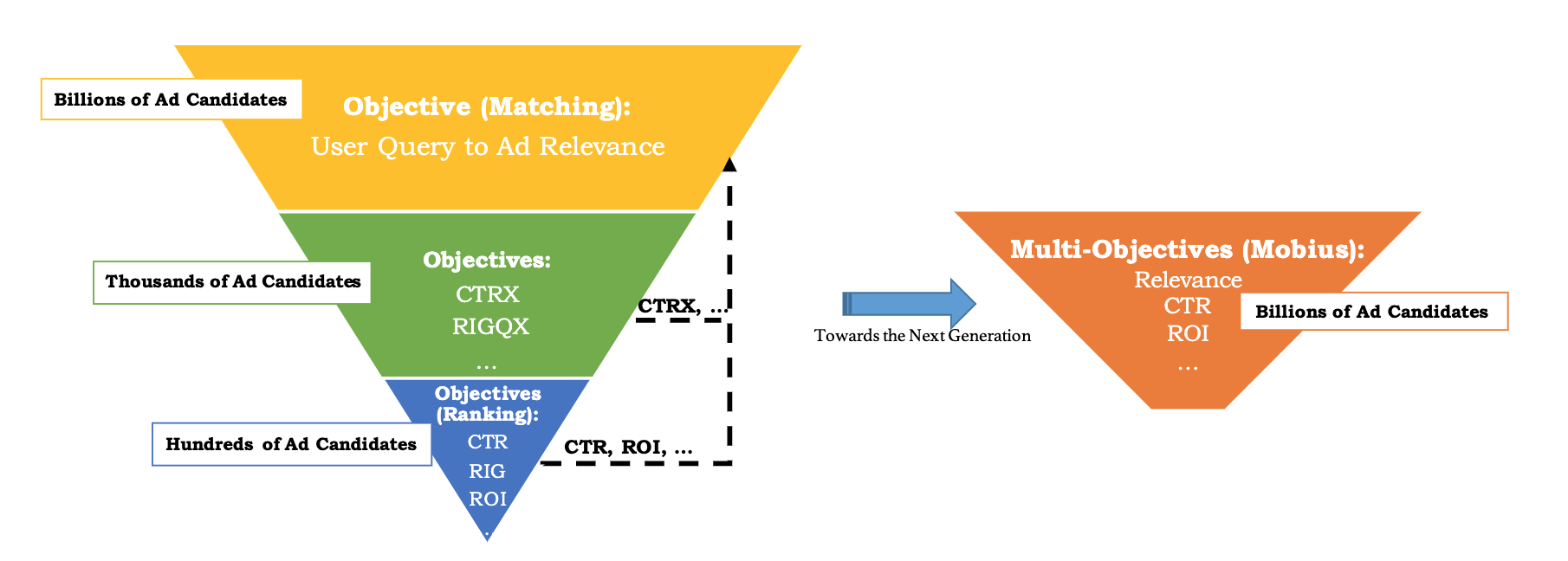
Fig. 2. Mobius 期望将 query-ad 相关性的学习目标和许多其他业务指标统一在一起,具有响应延迟低、计算资源受限、对用户体验影响小的特点。(Image source: M Fan et al.)
但这样做存在以下两个难点:
-
点击历史不足: 排序模型的训练数据往往都是高频展示的 ad 和高频的用户 query 组成的 pair。这导致排序层往往会出现只要 ad 或 query 中的某一方是高频的情况下,模型预测出很高的点击率,尽管此时 ad 和 query 可能是不相关的。
-
高计算/存储代价: Mobius 的设计理念下,模型需要对数以亿计的 query-ad pair 进行打分,难免遇到计算和存储瓶颈。
针对难点 1,Mobius 采用了类似 “teacher-student” 结构的主动学习框架来增强数据,具体来说,其设计了一个数据生成器构建合成 query-ad pair,这些合成的 pair 将会交给一个擅长衡量 query 和 ad 语义相关性的 teacher agent(衍生自召回层)进行判断,来帮助模型找出 high CTR but low relevance 的 badcases,而后点击率模型作为 student,通过得到额外的 badcases 来提高长尾查询和广告的泛化能力;针对难点 2,使用 SOTA 的近似最近邻(approximate nearest neighbor,ANN)搜索和最大内积搜索(Maximum InnerProduct Search,MIPS)技术来提升索引和检索大量广告的效率。具体的细节在后文会交待。
方案
Mobius 的设计逻辑使得召回层将直接面对数以亿计的 query-ad pair 对,模型的输入样本增长巨大,因此需要重新设计模型的训练细节。
Active-Learned CTR Model
百度使用 DNN 作为 CTR 模型的 backbone 已有 6 年的时间,DNN 模型具有很强的记忆性(memorization),但是对于长尾分布下的长尾数据的泛化能力欠佳。以下图 3 为例,(Tesla,Mercedes-Benz)是一个高频出现的 query-ad pair,因此模型能够很好地建模他们的 CTR 分数,但是对与低频词 White Rose,CTR 模型反常的给出了较高的 CTR 预估分,可见在 DNN 模型对于长尾数据的泛化能力不能令人满意,而百度分析了很多用户的 query 和 ad 点击日志,发现用户饱受这种长尾数据和冷启动问题的影响。

Fig. 3. 百度之前的 CTR 模型的一些 badcases,由于训练数据大部分被高频的 query-ad pair 所支配,可以看出对于一些低频次对 (White Rose, Mercedes-Benz) 模型给出了很高的 CTR 预估分。(Image source: M Fan et al.)
为了缓解上述问题,Mobius 通过主动学习的方式,采用原来的三层漏斗框架中的召回层作为 teacher 来指导作为 student 的新 CTR 模型感知那些 low-relevance 的 query-ad pair,进而获取额外的相关性知识。如下图 4 所示,这种主动学习的范式主要包含两部分,数据增强以及 CTR 模型训练。
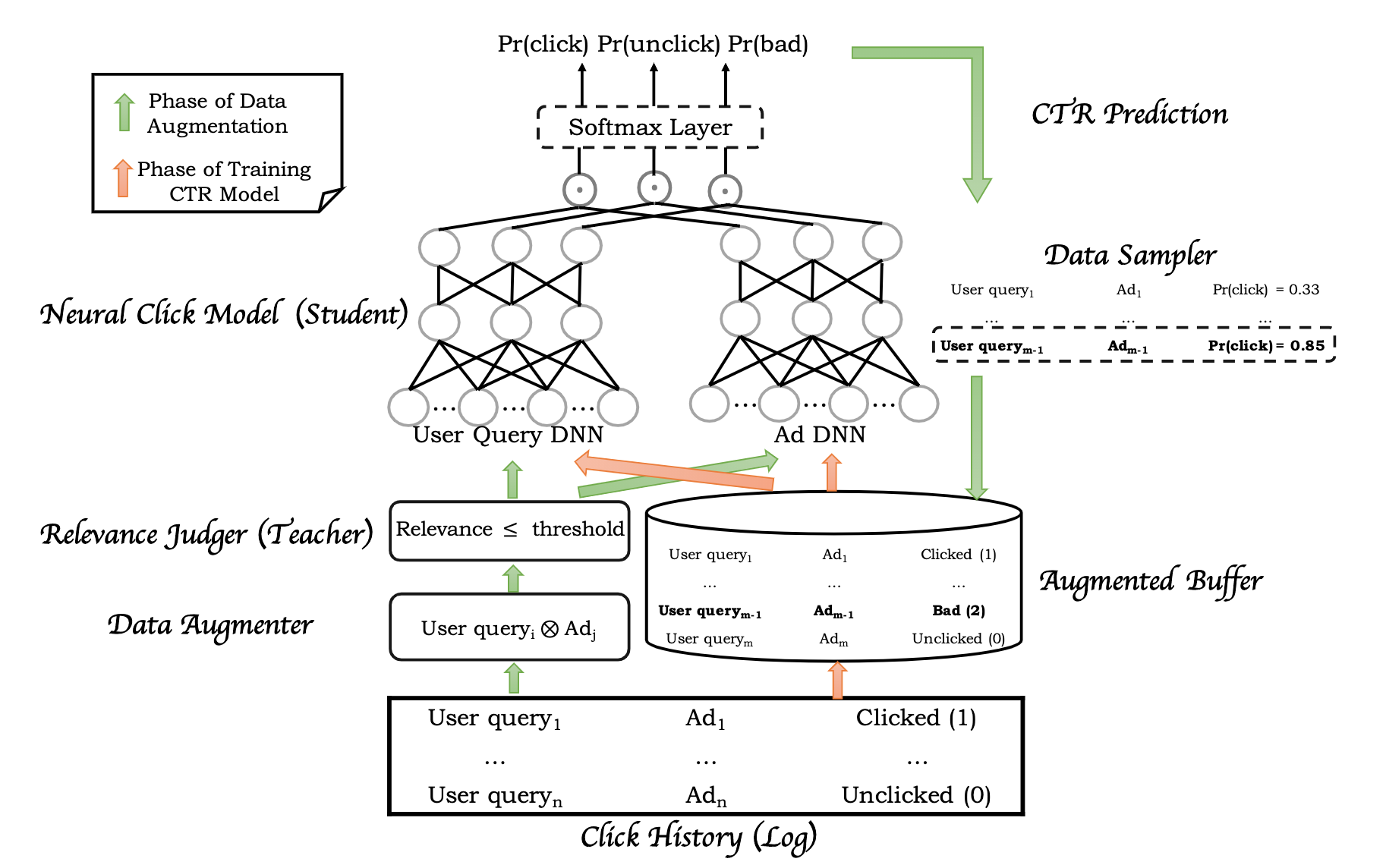
Fig. 4. Mobius 所采用的主动学习框架,其主要包含两个部分:数据增强 & CTR 模型训练。 (Image source: M Fan et al.)
数据增强
首先,数据增强模块(Data Augmenter)会读取一个 batch 的数据,主要是用户的真实 query-ad pair。每当 Data Augmenter 读到数据后,就会进行 cross-join 操作($\bigotimes$)来构建生成更多的 query-ad pair。如果有 $m$ 个 query 和 $n$ 个 ad,那么经过 cross-join 操作后,将会生成 $m \times n$ 个 query-ad pair,随后这些 pair 将会输入到 Relevance Judger 中进行相关性打分,在这里会设置一个阈值来获取 low-relevance pair。
最后,这些 low-relevance pair 将会喂给 CTR 模型,进行三分类训练(click,unclick,bad)来帮助模型识别那些 low relevance but high CTR 的样本。在这里,也可以设置的一个更小的阈值来过滤掉一些特别不相关的样本,但是为了保留数据增强的可探索性,这里 Mobius 设计了一个采样器,用于采样那些真正的 low relevance but high CTR 样本(增强的数据都会经过 CTR 模型,但只有部分 pair 会得到一个较高 CTR 值)并给它们打上一个 bad 标签。
CTR 训练
所有的用户点击历史和 Data Augmenter 生成的数据都会输入到模型中训练,具体的模型设计则是稀疏 DNN 结构,并且采用的是双塔结构(user-side 和 ad side)。user-side 的输入是用户 profile 信息和 query 信息,ad-side 的输入是 ad 的 embedding,每个塔都会得到一个 32*3 维的向量,并计算三次内积最后进行 softmax 得到分类预测结果。
整个流程中,CTR 模型 (student) 可以主动向相关性模型 (teacher) 查询标签,以提高其对数以亿计的 query-ad 长尾数据的 CTR 预测泛化能力。这种类型的迭代监督学习被称为主动学习,其算法的伪代码可以见下表 1。

Fast Ads Retrieval
线上服务的时候,我们需要找到和用户 query 最相关并且具有较高 CPM 的候选 ad,但是通过暴力方法遍历所有的候选集显然是不切实际的,为了满足低延迟的要求,Mobius 采用了 ANN 搜索来加速检索过程,如下图 5 所示,ANN 首先对输入的 user 和 ad 向量进行压缩节省内存,随后可以应用两种策略:1)通过余弦距离进行 ANN 搜索并按照 BRW (Business Related Weight) 进行策略重排;2)利用权值进行排序,这是一个最大内积搜索 (MIPS) 问题。
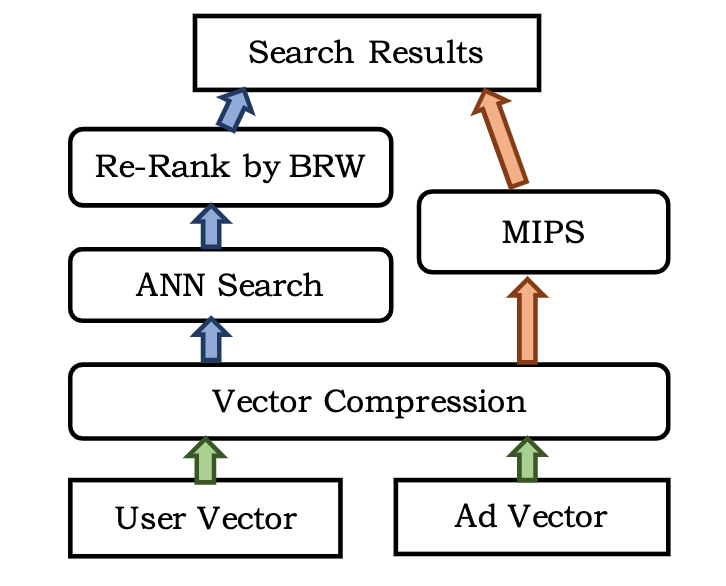
Fig. 5. Mobius 所采用的近似最近邻 ANN 方法。 (Image source: M Fan et al.)
ANN Search
由图 4 可知,softmax 输入是双塔向量的余弦值,因此最终得到的 CTR 分是和向量的余弦距离单调相关的,因此模型训练完成并服务的时候,我们可以通过计算模型 inference 出来的 user 向量和 ad 向量的余弦距离排序来完成 CTR 排序任务。ANN 搜索从原理上简单来说就是,仅通过扫描很小比例的数据来找出和 query 最相似的对象集,ANN 的相关简介可以看这里。
MIPS
在上面的 ANN 解决方案中,在 user 向量和 ad 向量匹配之后,考虑了与业务相关的权重信息。实际上,这个权重在排名中至关重要。为了在排序时更早的考虑权重信息,我们通过一个加权余弦问题将快速排序过程形式化为下式:
\[\cos (x, y) \times w=\frac{x^{\top} y \times w}{\|x\|\|y\|}=\left(\frac{x}{\|x\|}\right)^{\top}\left(\frac{y \times w}{\|y\|}\right)\]其中,$w$ 表示业务相关权值,$x,\ y$ 表示 user-query 和 ad 的 embedding,注意,加权余弦带来了一个内积搜索问题,通常称为最大内积搜索(MIPS)。
Vector Compression
在数据量上亿的情况下,存储高维 float 型特征向量的代价是很高的,并且当我们需要加载到内存中时也是十分困难的。一种方法是将这些 float 型向量压缩为随机的 binary/int 哈希编码(hash codes)或者是量化编码(quantized codes)。这种压缩方式虽然在一定程度上降低检索召回率,但可以带来显著的存储效益。在 Mobius 的实现中,百度采用了 K-Means 等量化方法对索引向量进行聚类,而不是对索引中所有 ad 向量进行排序。当用户的 query 到来时,首先找到 query 向量所分配到的聚簇索引,然后从索引中获取属于同一聚簇内的 ad。积量化(product quantization,PQ)进一步将向量分解为若干子向量,并对每个子向量分别进行聚类。图 4 中,Mobius 也在输入到 Softmax Layer 之前将 user vector 和 ad vector 都划分为 3 个 32 维的三元组子向量,每个子向量可以被分配到一个三元组的聚簇 centroids。例如,如果我们为三元组中的每个子向量选择 $10^3$ 个 centroids,就可以列出 $10^9$ 个可能的聚类中心,这对于 10 亿量级的广告建立索引来说是足够的。在 Mobius 中,采用了一种称为最优积量化(OPQ)的算法,最终在耗时和召回覆盖率上均有较大的提升。
小结
这篇论文的模型结构设计比较新颖,将传统的召回和排序流程合并优化,有效的减少了两者之间的 gap。其中,关于样本的设计思路非常值得借鉴,在 batch 内 cross join 本身不是很惊奇的操作,但是后续通过相关性筛选和 ctr 预估来采样 low relevance but high CTR 的样本十分有趣,可以有效的缓解模型在长尾数据上泛化不足的问题。关于 Mobius 所使用的的采样方法,其实从根本思路上来说和 Facebook 的 EBR 有着很相似的目标,就是通过采样来解决长尾数据的泛化能力,更好的拟合真实的数据分布,联系一下 Kaiming He 等人的 MoCo 以及 Hinton 等人的 SimCLR 关于负样本设计的工作,我想这也就是所谓的“负样本为王”的原因。