这篇博客记录了我在工作中的遇到的一个小坑,主要是关于:为什么我的深度模型训练不起来?loss为啥不降?指标为啥不变?到底是谁偷走了我的梯度?
其实这个坑在 debug 之后回想一下细节,不得不感慨自己有些愚钝,又或者说还是自己的基础不够扎实,脑子里缺乏一些条件反射。当然,这也和我在 coding 前没有仔细思考有关系。
问题
Anyway,我遇到的问题是训练开始后模型的 loss 不降,对应的 AUC 指标也不变始终为 0.5,并且如下图 1,查看模型的各层参数也都不变为,权值恒为 0。 关于我的任务简单描述下:训练数据是两个视频(video_a,video_b)目标是判断两个视频的相似性,通过 DNN 层后对两个 video 的表示后计算内积结果,并作为交叉熵损失函数的 logits。
我使用的特征都是一些统计特征包含 categorical 和 real-value 特征,使用的类别特征和实值特征全部都经过了 embedding 处理,我的模型就是个简单的三层全连接 DNN,模型的 embedding 层全 0 初始化,DNN 参数层随机初始化,DNN 的 bias 全 0 初始化。可以保证数据集、模型的结构设计和训练过程无误。那么,为什么我的模型训练不起来呢?
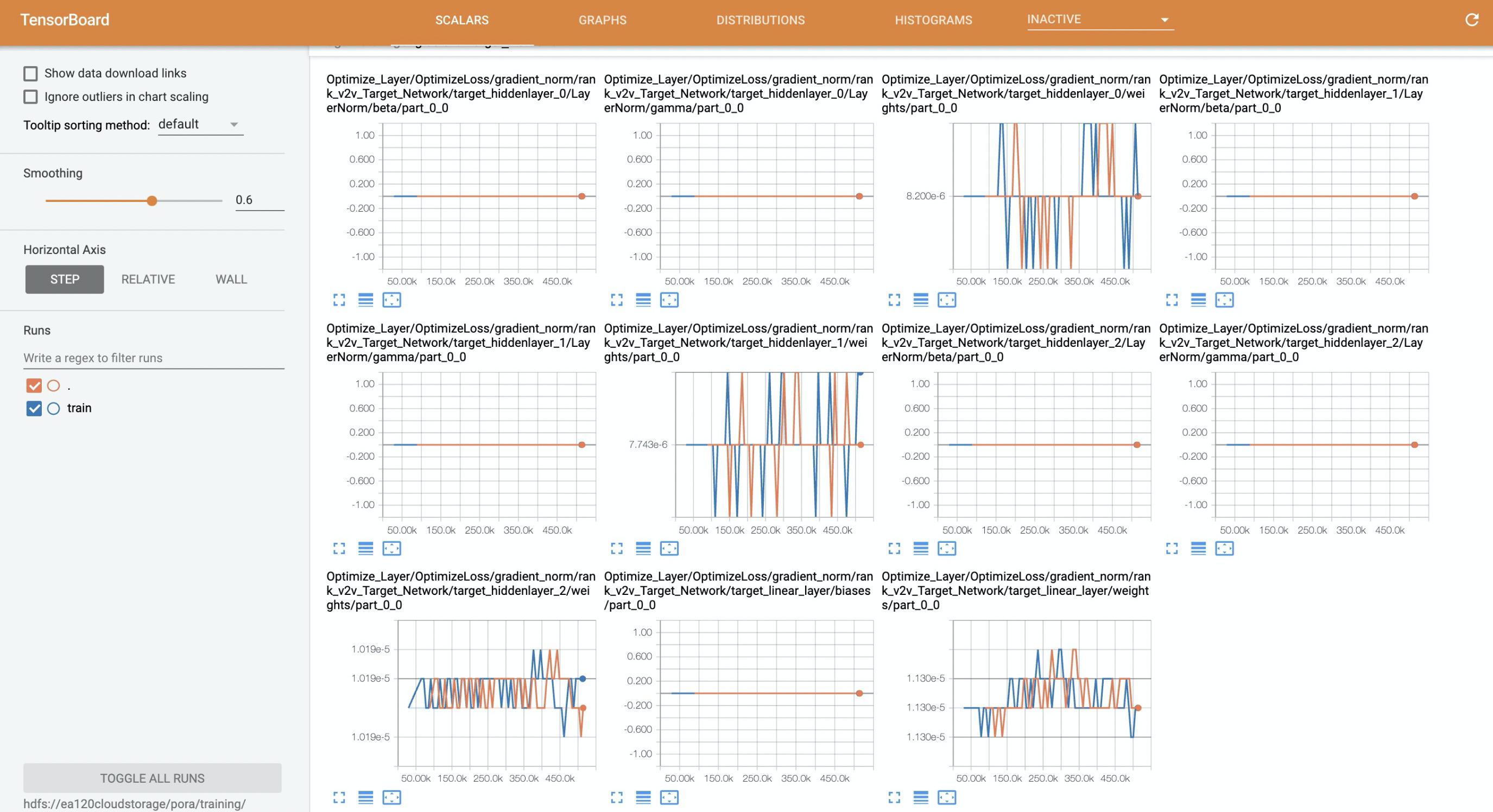
Fig. 1. 模型训练的 loss 和 auc 变化情况
探寻原因
可能经验丰富的人和脑子灵敏的人(是的,我就是脑子不灵敏的那个)已经知道了我的问题,那么针对那些暂时没想通的人,我们来看下一个 easy 案例,针对我的 case,我简化了一个 tiny 模型,输入数据只有一个 pair 对(video_a, video_b),代码里实际上是 video_a 和 video_b 经过 embedding 后的值。与此同时,我的模型也精简为一个简单的单层全连接,bias 初始化为 0,那么我运行如下的代码会发生什么呢?想想 ana 会怎么做
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
import tensorflow as tf
import numpy as np
a = tf.Variable(initial_value=[[0.,0.,0.,0.,0.,0.,0.,0.]])
b = tf.Variable(initial_value=[[0.,0.,0.,0.,0.,0.,0.,0.]])
label = tf.constant([[0.]])
W = tf.Variable(initial_value=np.random.rand(8,4), dtype=tf.float32)
B = tf.Variable(initial_value=np.zeros((1,4)), dtype=tf.float32)
vec_a = tf.matmul(a, W) + B
vec_b = tf.matmul(b, W) + B
cos = tf.multiply(vec_a, vec_b)
loss = tf.reduce_mean(
tf.nn.sigmoid_cross_entropy_with_logits(
labels=label,
logits=tf.reduce_sum(cos, keep_dims=True)
)
)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print("cos: ", sess.run(cos))
print("loss: ", sess.run(loss))
print("gradient of loss/cos: ", sess.run(tf.gradients(loss, cos)))
print("gradient of cos/W: ", sess.run(tf.gradients(cos, W)))
print("gradient of loss/a: ", sess.run(tf.gradients(cos, a)))
不卖关子了,上述代码是无法正常训练的,下面的是输出结果。
1
2
3
4
5
6
7
8
9
10
11
12
cos: [[0. 0. 0. 0.]]
loss: 0.6931472
gradient of loss/cos: [array([[0.5, 0.5, 0.5, 0.5]], dtype=float32)]
gradient of cos/W: [array([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]], dtype=float32)]
gradient of cos/a: [array([[0., 0., 0., 0., 0., 0., 0., 0.]], dtype=float32)]
至于原因嘛,看了输出结果想必就很清楚了,模型的梯度在 cos 之后就消失了,为什么会消失?这是因为:
\[cos = vec_a * vec_b = (a * W + B)(b * W + B) = ab \cdot W^2 + (aB + bB) \cdot W + B^2\] \[\frac{\partial{cos}}{\mathrm{d}W} = 2abW + aB + bB\] \[\frac{\partial{cos}}{\mathrm{d}a} = b\cdot W^2 + BW\]而由于 embedding 全 0 初始化,所以 $a$ 和 $b$ 初始值都为 0,那么无论原始数据是什么,对于 W 来说梯度都为 0,同样可以看出对于 embedding $a$ 来说,其梯度在 $B$ 初始化为 0 的时候同样为 0,因此 embedding $a$ 的梯度也为 0,那么模型自然是始终无变化,loss 和 AUC 也自然不变。如果 $B$ 初始化的时候不为 0,我们随机初始化 $B$ 结果如下,自然也就可以正常训练了(当然,第一次计算 $W$ 的梯度肯定也还是 0)。
1
2
3
4
5
6
7
8
9
10
11
12
cos: [[0.8982575 0.20215534 0.39968604 0.5663532 ]]
loss: 2.1856866
gradient of loss/cos: [array([[0.88759947, 0.88759947, 0.88759947, 0.88759947]], dtype=float32)]
gradient of cos/W: [array([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]], dtype=float32)]
gradient of cos/a: [array([[1.4191248, 1.7045877, 1.1545454, 1.0757841, 1.7959626, 1.9317265, 1.3685277, 1.88685 ]], dtype=float32)]
发散一下
是不是感觉挺 “easy” 的 = =。但是你不去静下心的想,很容易忽略这个问题,你可能要问为什么会全 0 初始化,这是因为我们的模型的特征是不断迭代的,为了防止新加入的特征对模型影响过大,我们会对新的 embedding 特征进行全 0 初始化,但是当你 train from new 的时候如果忽略掉了这个初始化的细节,emmmm,结果就是像我一样在这为了个愚蠢的 bug 写 blog。(逃
留个课后小作业,如果我用 video 组成三元组并使用 triplet_loss 来训练模型,一个简化的代码如下,仍然使用 embedding 全 0 初始化,结果会如何?以及为什么会出现这个结果?思考清楚你就会发现掌握原理还是重要的,不能当个调包侠啊!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
import tensorflow as tf
import numpy as np
a = tf.Variable(initial_value=[[0.,0.,0.,0.,0.,0.,0.,0.]])
b = tf.Variable(initial_value=[[0.,0.,0.,0.,0.,0.,0.,0.]])
c = tf.Variable(initial_value=[[0.,0.,0.,0.,0.,0.,0.,0.]])
label = tf.constant([[1.]])
W = tf.Variable(initial_value=np.random.rand(8,4), dtype=tf.float32)
B = tf.Variable(initial_value=np.zeros((1,4)), dtype=tf.float32)
vec_a = tf.matmul(a, W) + B
vec_b = tf.matmul(b, W) + B
vec_c = tf.matmul(c, W) + B
dist_rp = tf.square(vec_a - vec_b)
dist_rn = tf.square(vec_a - vec_c)
loss = tf.reduce_mean(
tf.maximum(0.0, 0.314 + dist_rp - dist_rn)
)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print("dist_rp: ", sess.run(dist_rp))
print("loss: ", sess.run(loss))
print("gradient of loss/dist_rp: ", sess.run(tf.gradients(loss, dist_rp)))
print("gradient of loss/W: ", sess.run(tf.gradients(loss, W)))
print("gradient of loss/a: ", sess.run(tf.gradients(loss, a)))