这是 Licheng Yu, Yen-Chun Chen, Linjie Li 在 CVPR 2020 上发表的关于视觉-语言方面的自监督学习演讲,本文进行一些梳理以及记录个人的理解。
自监督学习在近两年已然成为机器学习研究的一个热门方向,在 CVPR 2020 中,也有很多相关的论文提出,Licheng Yu, Yen-Chun Chen, Linjie Li 在 CVPR 2020 上的进行了主题为“Self-supervised Learning for Vision-and-Language”演讲,主要和视觉-语言相关的自监督学习,下面是具体的内容梳理和分析。
- Introduction
- Self-supervised Learning for Image-and-Language
- Self-supervised Learning for Video-and-Language
Introduction
数据、算法和算力已经成为当今机器学习的“三驾马车”,传统的数据构成为“数据集”加“标签”。然而带标签数据的获取成本极高,以 MS COCO 数据集为例,其包含 120000+ 张图像,每章图像有 5 个句子描述,加上后期的各种处理,整个数据集的成本高达 $10w! 向巨佬们低头
自监督学习的出现有效的缓解了数据获取成本过高的难题,在 CV 领域上最近两年提出的一些自监督学习方法甚至可以接近监督方法的性能(ResNet50 as backbone)。近两年代表性的自监督模型有 CPC、CMC、MoCo 和 SimCLR。
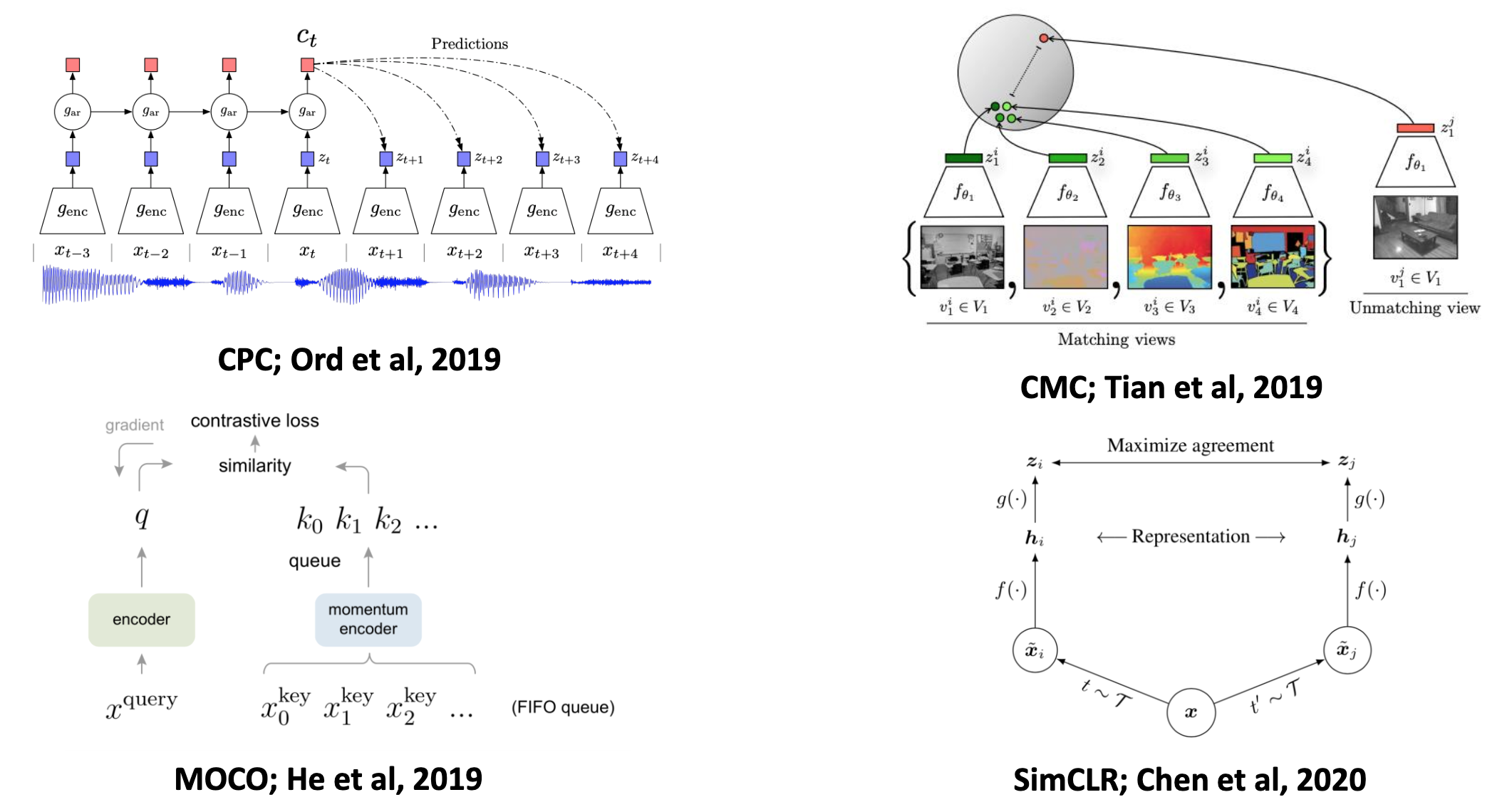
Fig. 1. 几个代表性的自监督视觉学习算法. (Image source: Licheng Yu et al.)
这些方法一般会设置一个辅助任务(pretext task)帮助模型学习到与下游任务无关的预训练表示,常见的辅助任务有:图像着色(Image Colorization)、图像修补(Image Inpainting)、拼图(Jigsaw puzzles)以及相对位置预测(Relative Location Prediction)。

Fig. 2. 常见的几个视觉自监督模型所使用的辅助任务(pretext task). (Image source: Licheng Yu et al.)
而在 NLP 领域上,经典的自监督学习模型则有 BERT 和 GPT series。它们都使用了大规模的网络语料数据,例如 Wikipedia 和 BBC News,区别在于模型设计有所不同,例如 BERT 是双向语言模型使用了 Masked Language Model 这种特殊的辅助任务;而 GPT series 遵循传统语言模型的设计,仍然是单向语言模型,保持模型的生成能力。无论是 CV 还是 NLP,大部分的自监督模型都遵循下图所示的训练框架,pre-training task 一般就对应 pretext task。
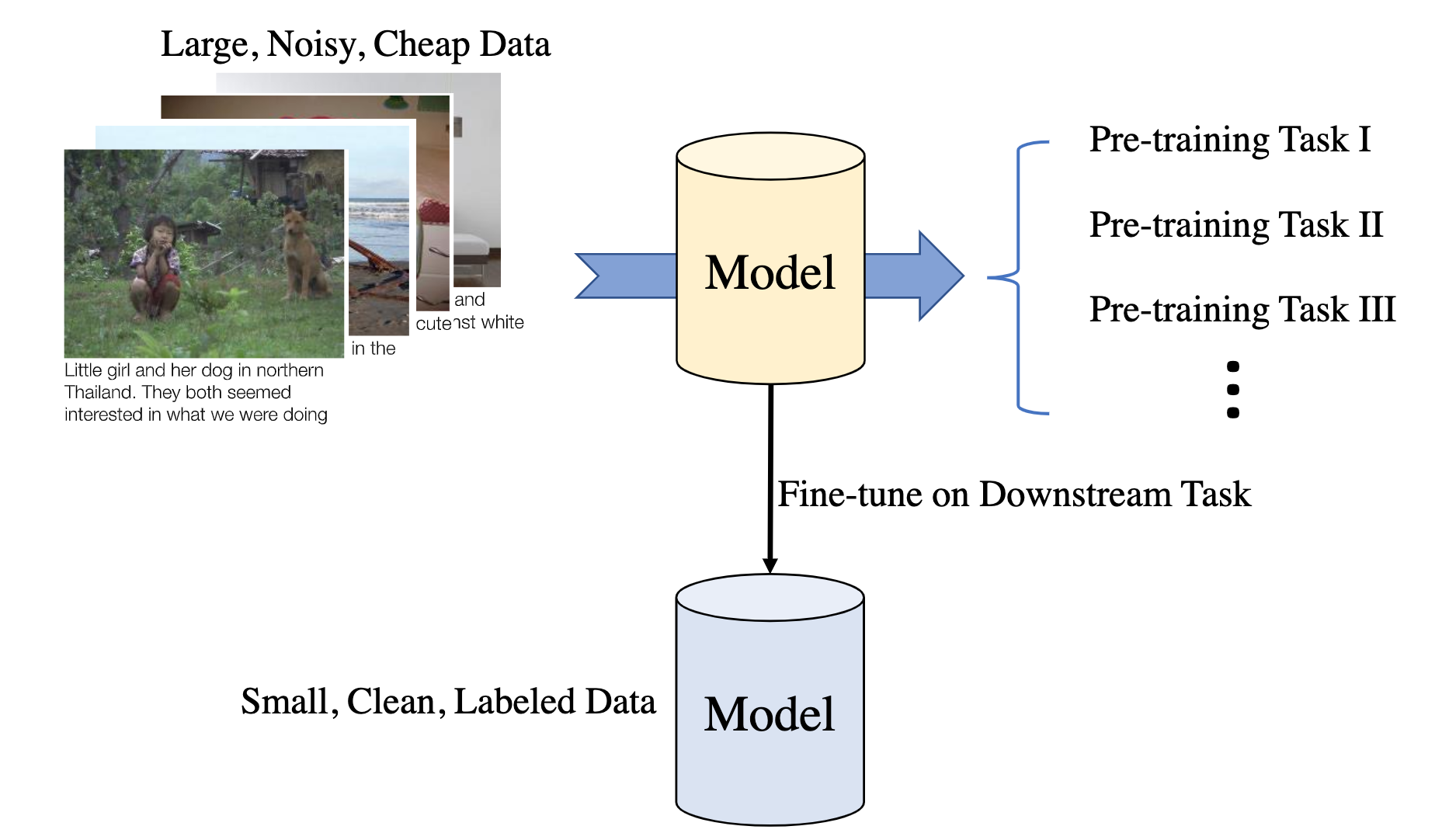
Fig. 3. Pre-training + Finetuning 两阶段 pipeline. (Image source: Licheng Yu et al.)
下图展示了 Image-Text 和 Video-Text 各自方向的重要模型发展简史,对于 Image-Text,常见的下游任务有 VQA、CVR、NLVR2 等等,而对于 Video-Text 常见的下游任务则有 Video QA、Video Captioning 等。
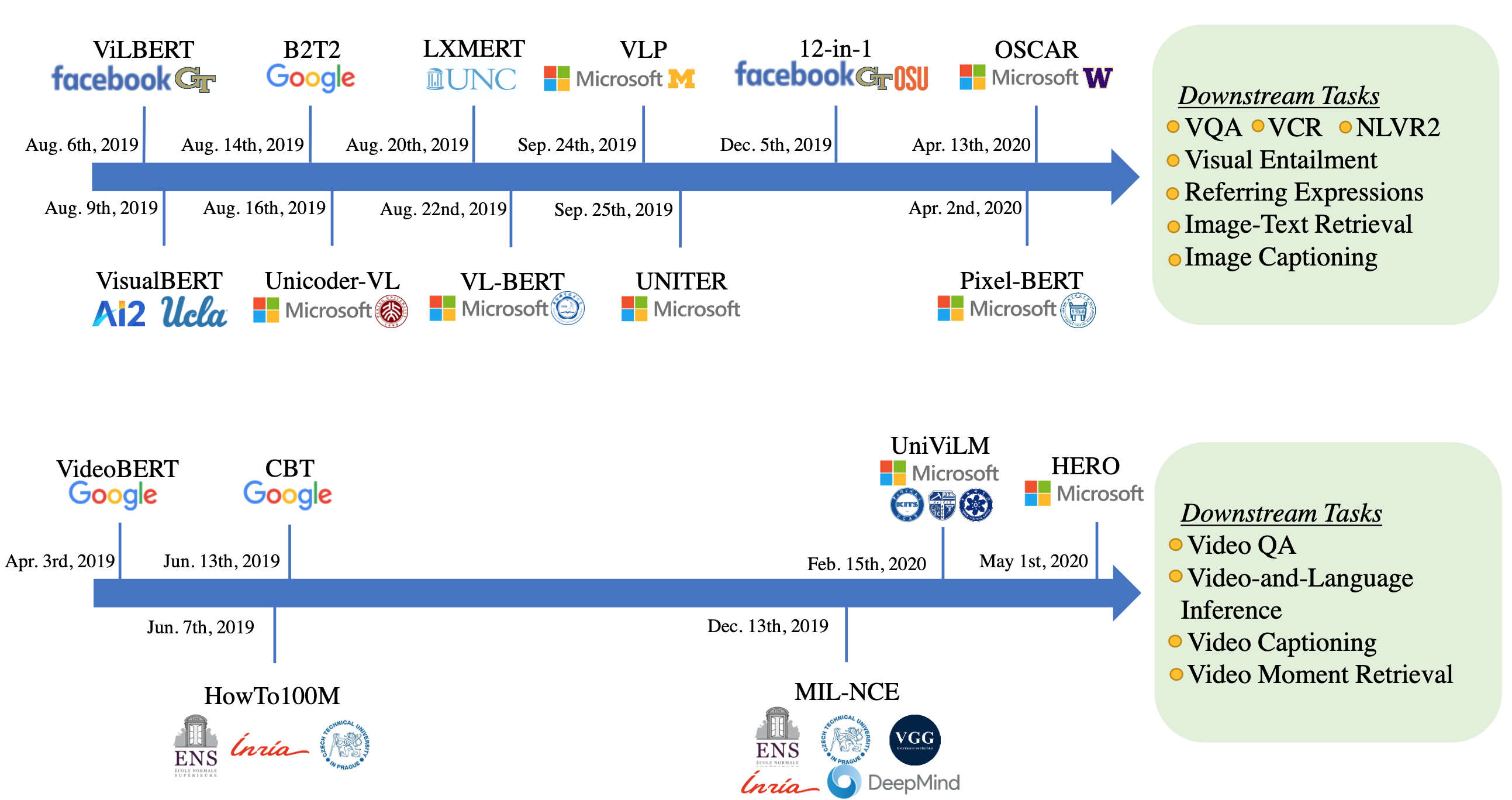
Fig. 4. Image-and-Language & Video-and-Language 重要模型发展简史. (Image source: Licheng Yu et al.)
Self-supervised Learning for Image-and-Language
Image-and-Language 类的自监督学习算法,按模型框架如下图,可以分为 Single-stream 和 Two-stream 两类。Single-stream 类方法将 image 的 region 和 text 的 token 进行简单的处理之后统一输入到自注意 Transformer 结构中,Two-stream 略有不同,来自不同模态的 token 首先独立的通过模态内的自注意 Transformer 提取模态内信息,然后输入到交叉注意力的 Transformer 中进行模态信息融合。
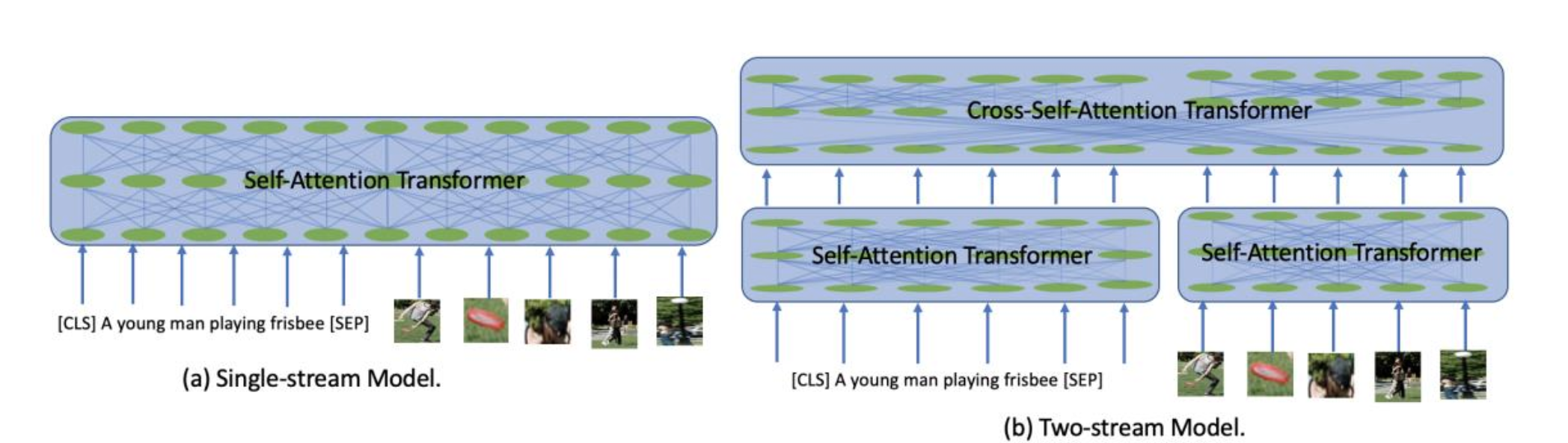
Fig. 5. Single-stream and Two-stream 模型框架示意图. (Image source: J Cao et al.)
Pretraining Tasks
下面以 Single-stream 的模型 UNITER 算法为例,讲解 Image-and-Language 自监督学习方法的常见预训练任务,UNITER 使用了三个预训练任务:Masked Language Modeling (MLM)、Masked Region Modeling (MRM) 和 Image-Text Matching (ITM)。
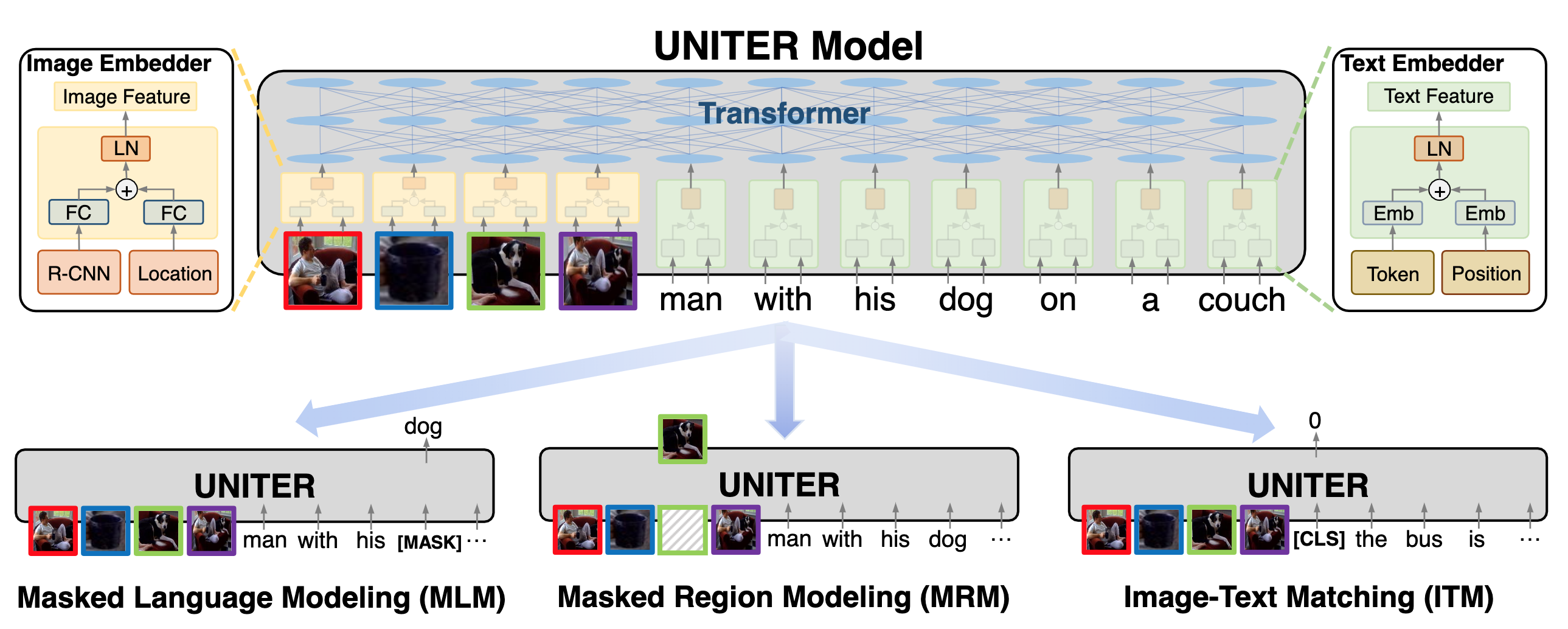
Fig. 6. UNITER 算法的预训练算法示意图. (Image source: YC Chen et al.)
-
Masked Language Modeling (MLM)
假设输入的图像 region 的表示为 \(\mathbf{v}=\left\{v_{1}, \ldots, v_{K}\right\}\),输入的句子 token 表示为 \(\mathbf{w}=\left\{w_{1}, \dots, w_{T}\right\}\),被 mask 的单词 token 为 $\mathbf{m}$,则 MLM 部分的损失函数为如下式,相比于 BERT 的区别在于加入了 image 模态的 region 特征。
\[\mathcal{L}_{\mathrm{MLM}}(\theta)=-E_{(\mathbf{w}, \mathbf{v}) \sim D} \log P_{\theta}\left(\mathbf{w}_{\mathbf{m}} \mid \mathbf{w}_{\backslash \mathbf{m}}, \mathbf{v}\right)\] -
Masked Region Modeling (MRM)
这部分的设计是参考 MLM 来实现的,UNITER 的作者设置了三种不同的训练机制,但都遵循以下的损失函数设计:
\[\mathcal{L}_{\mathrm{MRM}}(\theta)=E_{(\mathbf{w}, \mathbf{v}) \sim D} f_{\theta}\left(\mathbf{v}_{\mathbf{m}} \mid \mathbf{v}_{\backslash \mathbf{m}}, \mathbf{w}\right)\]具体到三种不同的训练方式上,首先第一种形式,Masked Region Feature Regression (MRFR),如下图所示,MRFR 方式试图通过 Transformer 回归出被 mask 的 region 特征并计算 $L_2$ 损失来指导模型学习:
\[f_{\theta}\left(\mathbf{v}_{\mathbf{m}} \mid \mathbf{v}_{\backslash \mathbf{m}}, \mathbf{w}\right)=\sum_{i=1}^{M}\left\|h_{\theta}\left(\mathbf{v}_{\mathbf{m}}^{(i)}\right)-r\left(\mathbf{v}_{\mathbf{m}}^{(i)}\right)\right\|_{2}^{2}\]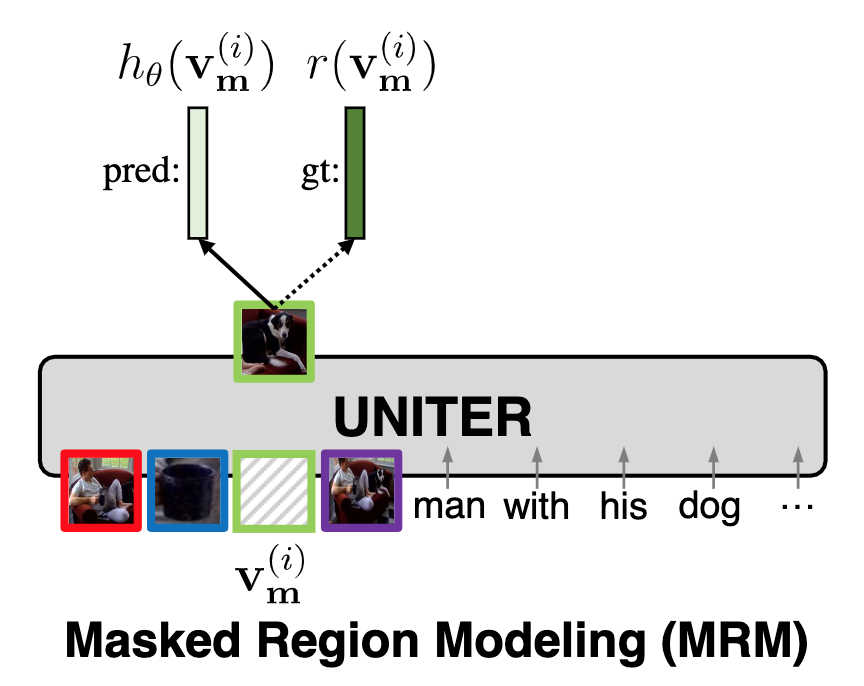
Fig. 7. Masked Region Feature Regression (MRFR)示意图. (Image source: YC Chen et al.)
第二种形式则是 Masked Region Classification (MRC),如下图所示,MRC 方式试图通过预测被 mask 的 region 对象的类别来指导模型学习,具体是将 Transformer 提取的特征经过 FC 层后进行 softmax 多分类得到归一化分布 \(g_{\theta}(\mathbf{v}_{\mathbf{m}}^{(i)}) \in \mathbb{R}^{K}\),最后再计算如下式所示的交叉熵损失。注意,每个 region 的类别 \(c(\mathbf{v}_{\mathbf{m}}^{(i)}) \in \mathbb{R}^{K}\) 是通过 Faster-RCNN 提取的。
\[f_{\theta}\left(\mathbf{v}_{\mathbf{m}} \mid \mathbf{v}_{\backslash \mathbf{m}}, \mathbf{w}\right)=\sum_{i=1}^{M} \operatorname{CE}\left(c\left(\mathbf{v}_{\mathbf{m}}^{(i)}\right), g_{\theta}\left(\mathbf{v}_{\mathbf{m}}^{(i)}\right)\right)\]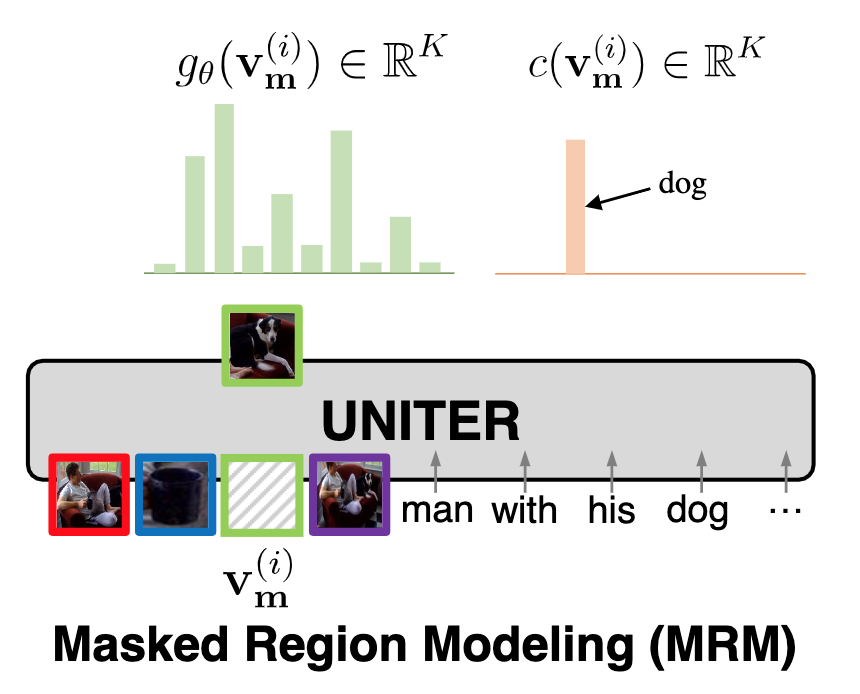
Fig. 8. Masked Region Classification (MRC)示意图. (Image source: YC Chen et al.)
最后一种形式则是 Masked Region Classification –KL Divergence (MRC-kl),MRC 方式通过 Faster-RCNN 提取 region 的唯一标签,这种做法可能存在问题。因此可以考虑使用 soft label,直接计算 Faster-RCNN 预测的分布与模型学习的分布的 KL 散度:
\[f_{\theta}\left(\mathbf{v}_{\mathbf{m}} \mid \mathbf{v}_{\backslash \mathbf{m}}, \mathbf{w}\right)=\sum_{i=1}^{M} D_{K L}\left(\tilde{c}\left(\mathbf{v}_{\mathbf{m}}^{(i)}\right) \| g_{\theta}\left(\mathbf{v}_{\mathbf{m}}^{(i)}\right)\right)\]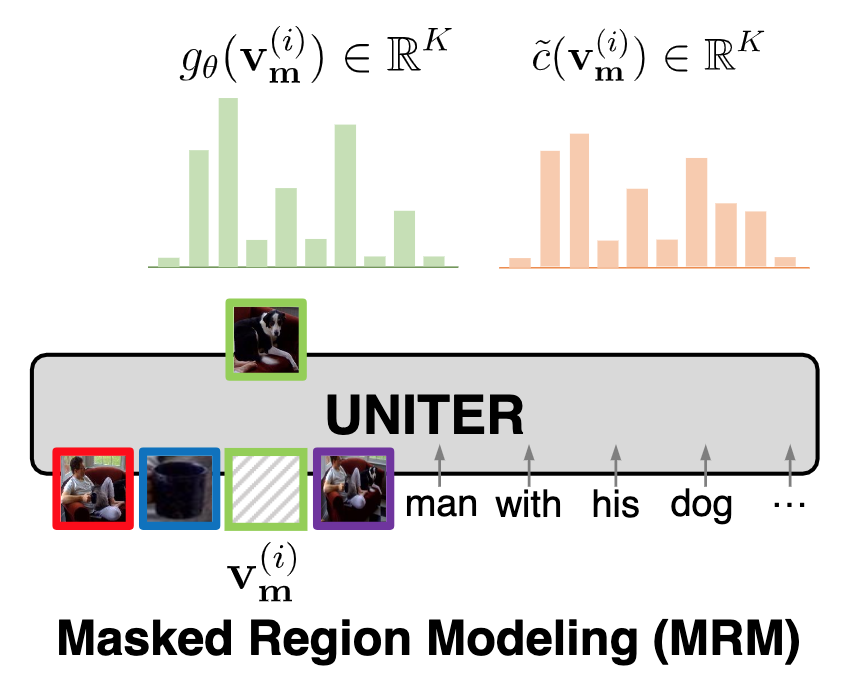
Fig. 9. Masked Region Classification – KL Divergence (MRC-kl)示意图. (Image source: YC Chen et al.)
-
Image-Text Matching (ITM)
ITM 任务需要一个 [CLS] token 代表融合后的表示,提取 [CLS] 表示后,通过 FC 层并 sigmoid 输出为一个 0~1 的 image-text 匹配得分 $s_{\theta}(\mathbf{w}, \mathbf{v})$,这部分的损失函数为下式所示的交叉熵损失,训练时的负样本通过随机替换正对样本中的 image/text 来构造。
\[\left.\mathcal{L}_{\mathrm{ITM}}(\theta)=-\mathbb{E}_{(\mathbf{w}, \mathbf{v}) \sim D}\left[y \log s_{\theta}(\mathbf{w}, \mathbf{v})+(1-y) \log \left(1-s_{\theta}(\mathbf{w}, \mathbf{v})\right)\right]\right)\]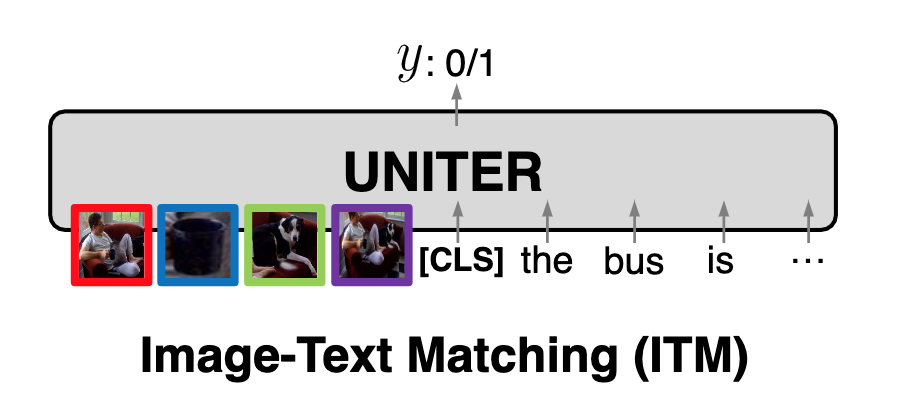
Fig. 10. Image-Text Matching (ITM)示意图. (Image source: YC Chen et al.)
除了上述的几个代表性预训练方法外,在其他的 Image-and-Language 自监督学习方法中,还有一些其他的预训练任务,例如 VLP 中的 Left-to-Right Language Modeling 以及 OSCAR 中的 Multi-View Alignment (tokens, tags, regions),这里不再展开赘述。
Optimization for Faster Training
为了加速模型的训练,Image-and-language 自监督学习方法往往会使用一些训练技巧,例如 Dynamic Batching,Gradient Accumulation 和 Mixed-precision Training。
-
Dynamic Batching
如下图所以,Transformer 使用 self-attention 因此其复杂度为输入序列长度的平方 $O(L^2)$,传统的序列 padding 方法是直接将序列长度 padding 到最长的长度,在某些情况下 padding 内容会很长,dynamic batching 的作用是将数据中长度相似的样本聚合 batching,这样就可以节省一部分算力。
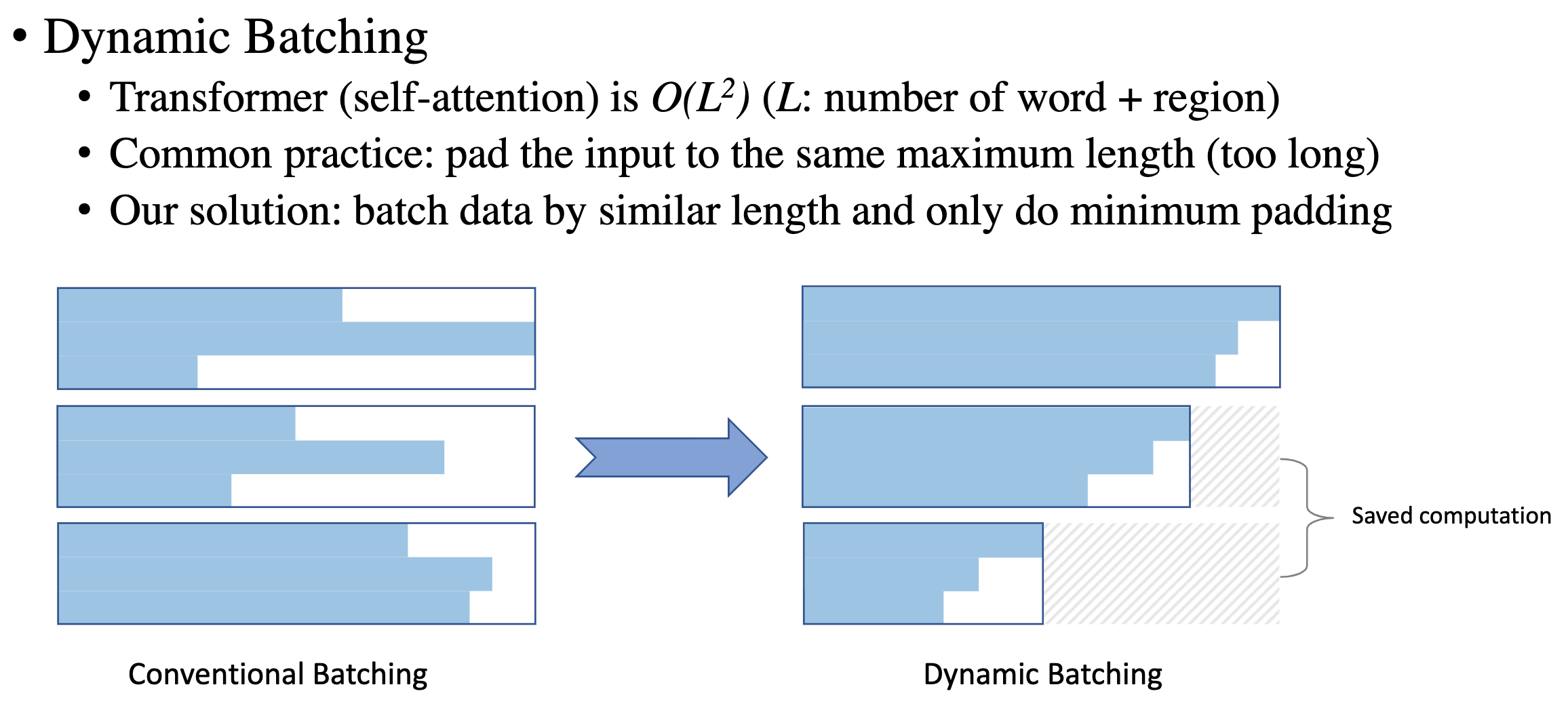
Fig. 11. Dynamic Bactching 加速效果示意图. (Image source: Licheng Yu et al.)
-
Gradient Accumulation
对于 Transformer 这种大型模型,其训练速度的瓶颈之一就是网络节点之间的通信开销,通过 Gradient Accumulation,减少通信的频率,可以有效地提升训练速度。
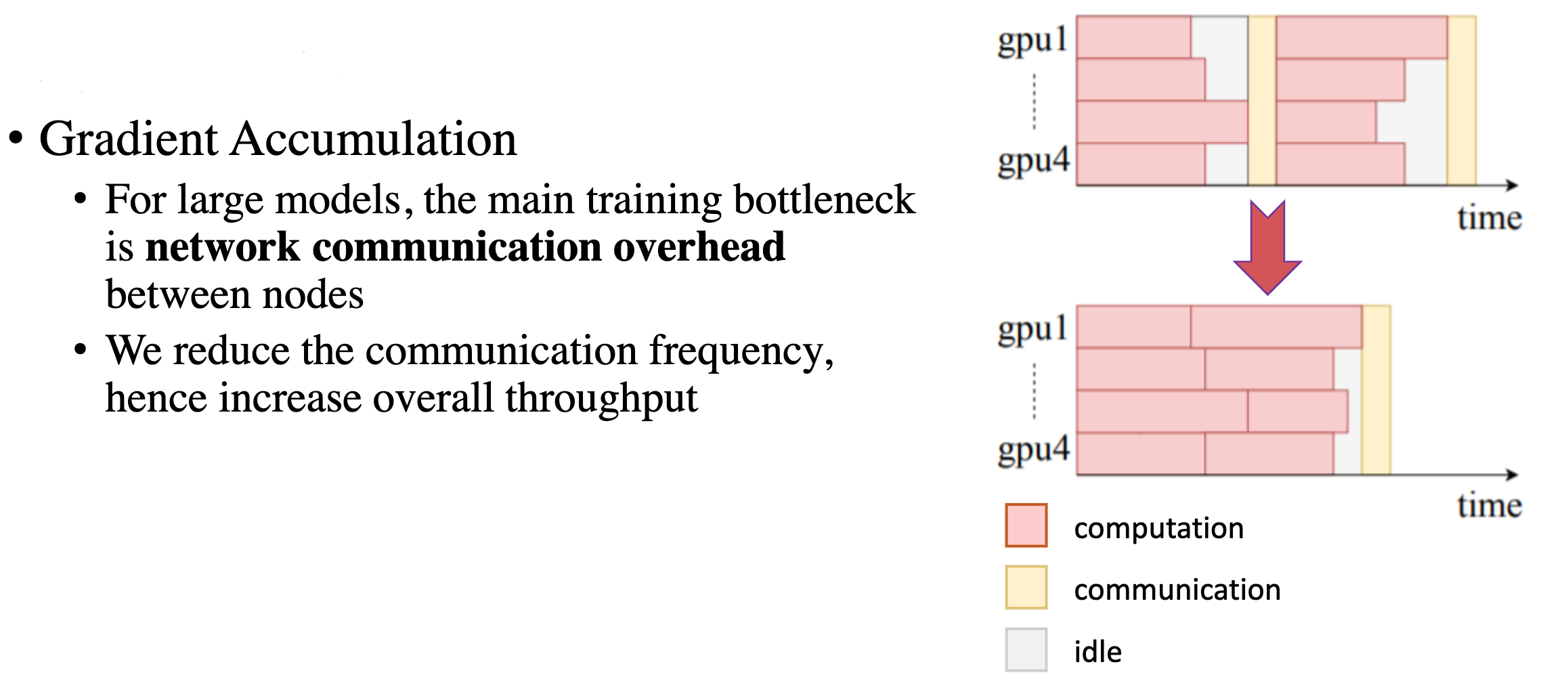
Fig. 12. Gradient Accumulation 加速效果示意图. (Image source: Licheng Yu et al.)
-
Mixed-precision Training
Mixed-precision Training(混合精度训练)通过 cuda 计算中的 half2 类型提升运算效率。一个 half2 类型中会存储两个 FP16 的浮点数,在进行基本运算时可以同时进行,因此 FP16 的期望速度是 FP32 的两倍。但要注意:
- 混合精度训练不是单纯地把 FP32 转成 FP16 去计算就可以了,只用 FP16 会造成 80% 的精度损失;
- Loss scaling:由于梯度值都很小,用 FP16 会下溢,因此先用 FP32 存储 loss 并放大,使得梯度也得到放大,可以用 FP16 存储,更新时变成 FP32 再缩放;
- 在涉及到累加操作时,比如 BatchNorm、Softmax,FP16 会上溢,需要用 FP32 保存,一般使用 GPU 中 TensorCore 的 FP16*FP16 + FP32 = FP32 运算。
整体流程:FP32 权重 -> FP16 权重 -> FP16 计算前向 -> FP32 的 loss,扩大 -> 转为 FP16 -> FP16 反向计算梯度 -> 缩放为 FP32 的梯度更新权重.
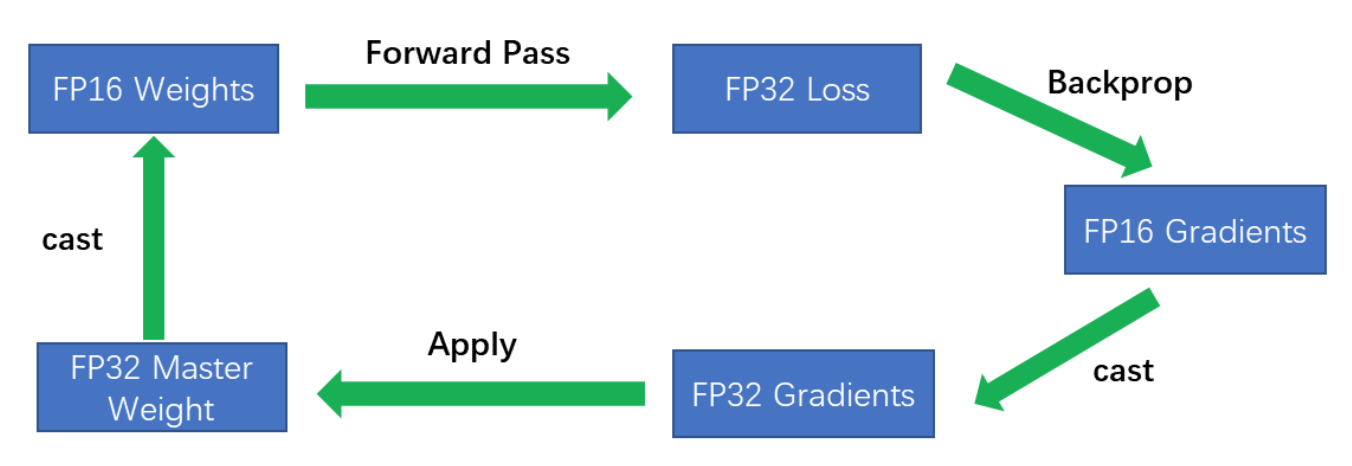
Fig. 13. Mixed-Precision Training 加速效果对比. (Image source: 李如)
Self-supervised Learning for Video-and-Language
Video-and-Language 自监督学习算法相对来说关注度更少,下面主要介绍几个近两年的算法。目前,Video-and-Language 领域的数据集主要是 TV Dataset 和 HowTo100M Dataset。
- HowTo100M
HowTo100M 数据集对应的论文中也提出了一个较为简单的自监督学习算法。如下图所示,Video 表示通过在 ImageNet 数据集上预训练的 ResNet-152 提取 2D 表示,而 3D 表示则通过在 Kinetics 数据集上预训练的 ResNeXt-101 提取,文本表示则通过预训练的 word2vec 提取嵌入表示。在训练时,video 和 text 的联合表示通过非线性映射得到,并使用 max-margin ranking loss 进行监督学习。
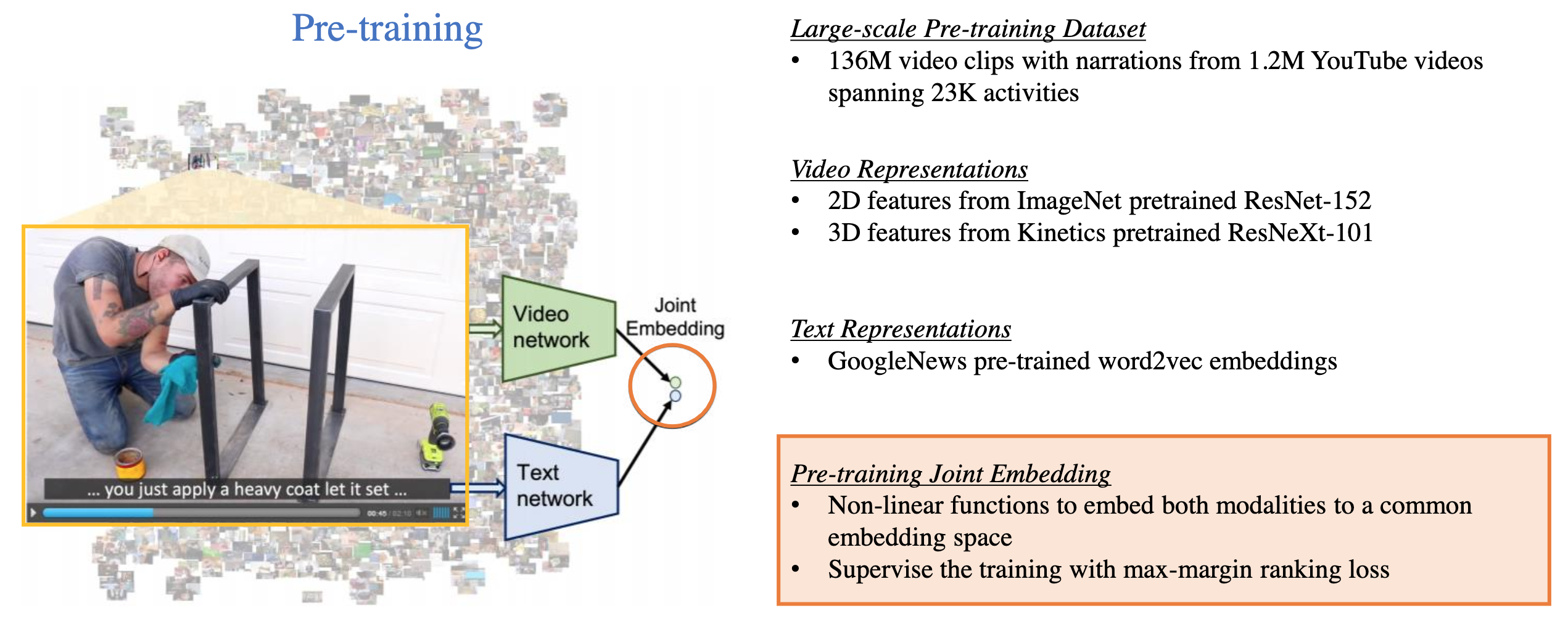
Fig. 14. HowTo100M 算法. (Image source: Licheng Yu et al.)
- VideoBERT
VideoBERT,使用 Transformer 进行训练得到 Video 和 Text 的联合表示,其中 Video 表示通过 Kinetics 数据集上预训练的 S3D 提取,同时通过分层 kmeans 将提取的 3D 表示得到 21K 个聚簇并对提取后的特征 token 化,最后一起输入 Transformer 进行预训练,预训练的任务主要是 Masked Language Modeling (MLM) + Masked Frame Modeling (MFM)。
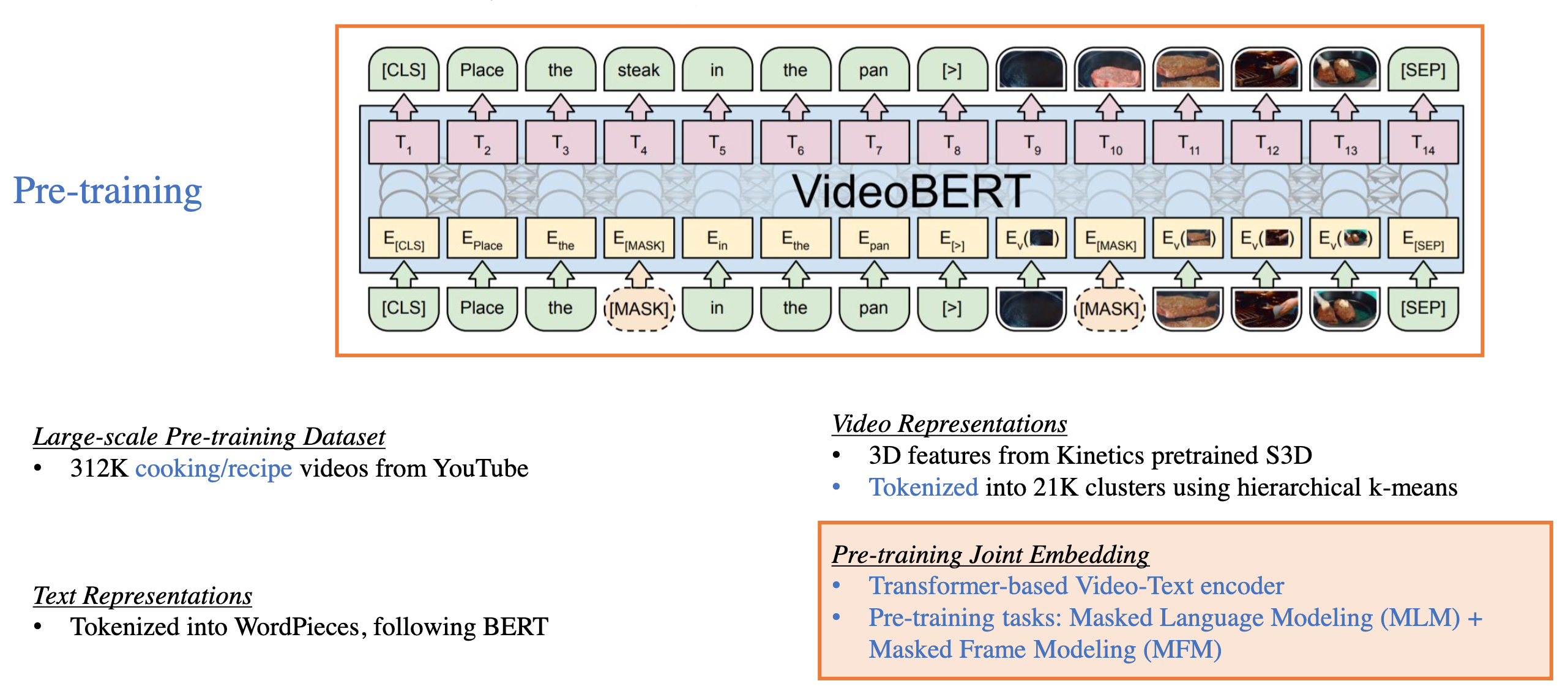
Fig. 15. VideoBERT 算法. (Image source: Licheng Yu et al.)
- CBT
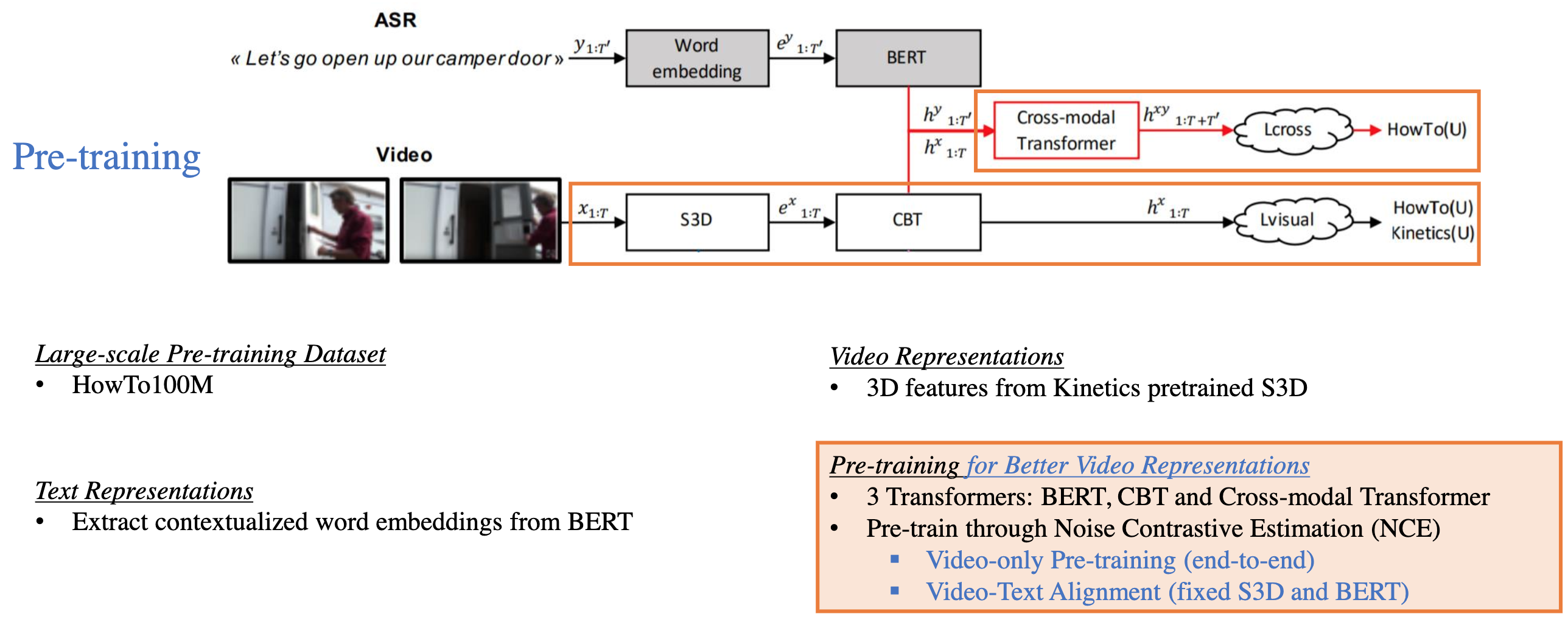
Fig. 16. CBT 算法. (Image source: Licheng Yu et al.)
- MIL-NCE
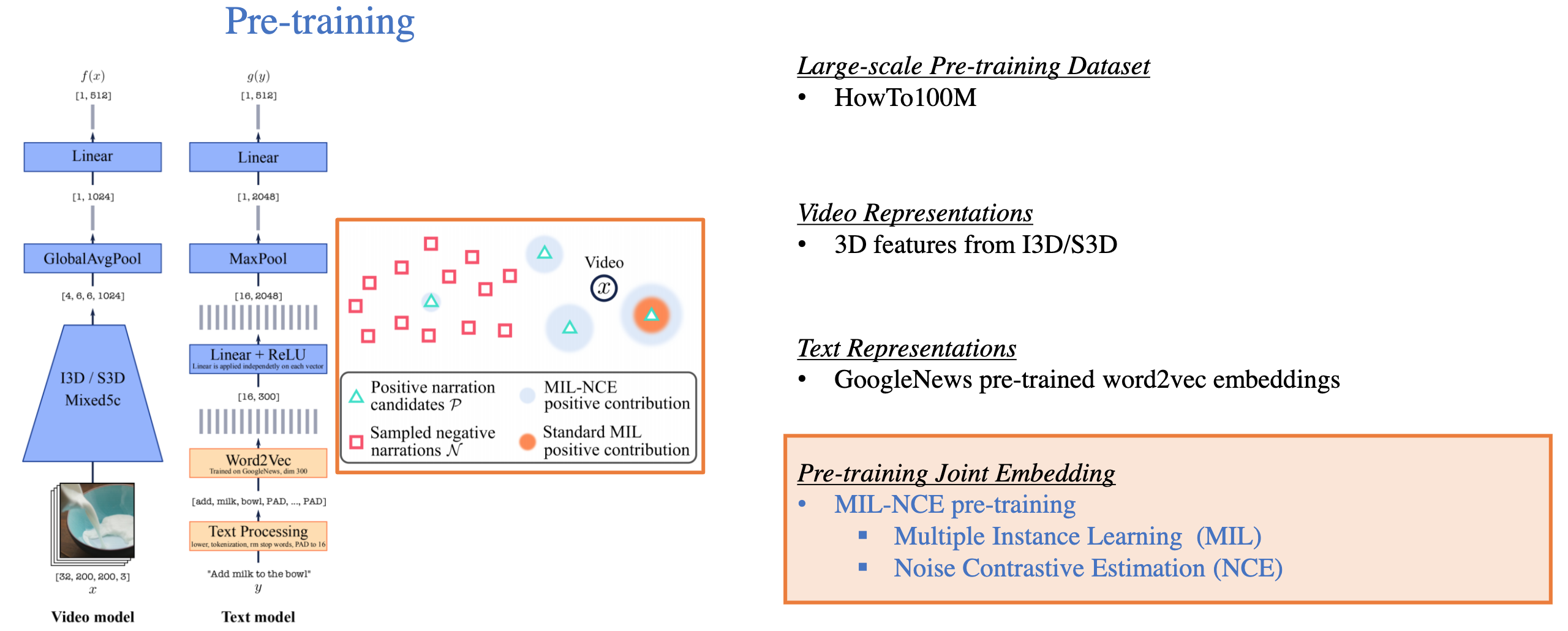
Fig. 17. MIL-NCE 算法. (Image source: Licheng Yu et al.)
- UniViLM
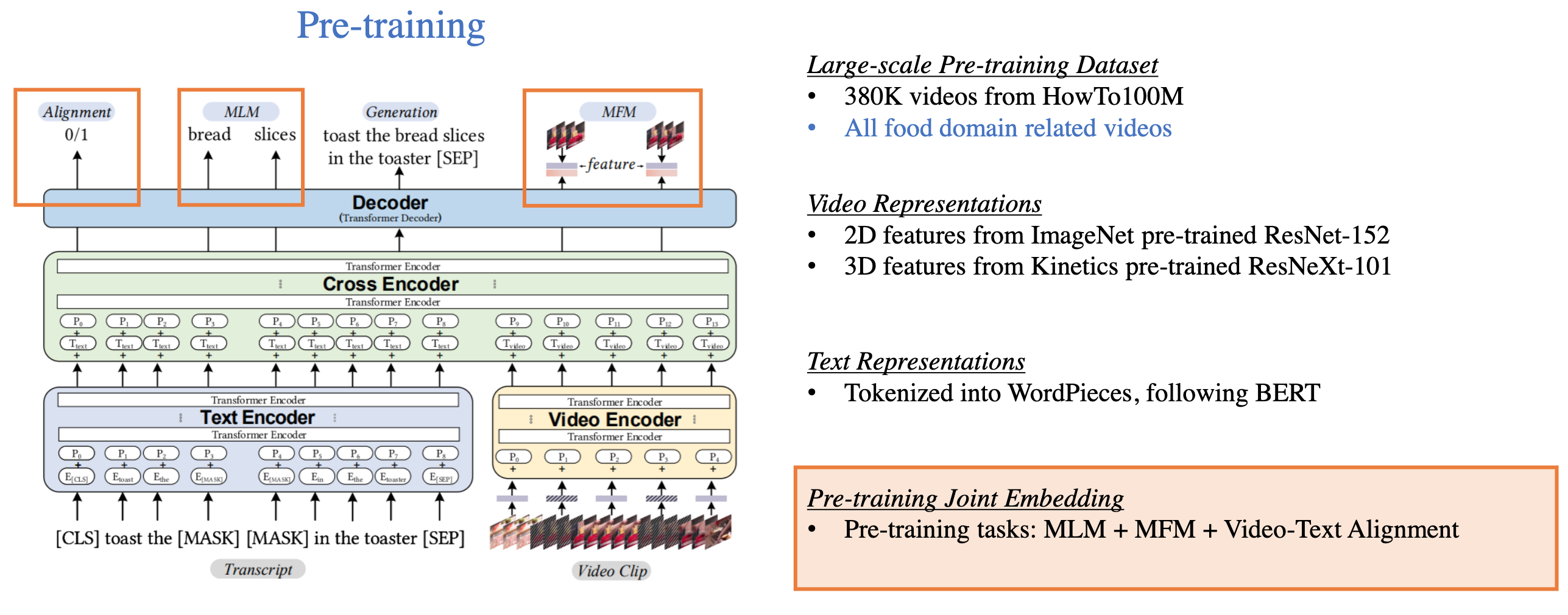
Fig. 18. UniViLM 算法. (Image source: Licheng Yu et al.)
整体来看,Video-and-Language 自监督学习仍处于初级阶段,video 表示和 text 表示是直接融合的,一定程度上丧失了时序对齐性。预训练任务方面也没有很大的创新,基本都是参考 Image-Text 领域,训练的数据集也受限,目前主要都是集中在 Youtube 视频上,这也导致能够拓展的下游任务相对“简单”。