多模态学习相关的论文阅读,包含多模态表示学习(Multimodal Representation Learning)、多模态检索(Multimodal Retrieval)、多模态匹配(Text-image Matching, etc.)以及多模态学习的一些应用实例.
随着 Web 技术发展,互联网上包含大量的多模态信息(包括文本,图像,语音,视频等)。从海量多模态信息搜索出重要信息一直是学术界研究重点。本文主要记录一些近期阅读的多模态论文阅读笔记。
- Adversarial Multimodal Representation Learning for Click-Through Rate Prediction — WWW 2020, Alibaba Group
- InterBERT: Vision-and-Language Interaction for Multi-modal Pretraining — KDD 2020 在投,Alibaba
- IMRAM: Iterative Matching with Recurrent Attention Memory for Cross-Modal Image-Text Retrieval — Tsinghua & Kwai, CVPR 2020
- Fine-grained Video-Text Retrieval with Hierarchical Graph Reasoning — Renmin University of China,CVPR 2020
- Graph Structured Network for Image-Text Matching —Chinese Academy of Sciences,CVPR 2020
- Pixel-BERT: Aligning Image Pixels with Text by Deep Multi-Modal Transformers —预印,University of Science and Technology Beijing & Microsoft Research
- Dense Regression Network for Video Grounding — South China University of Technology & Tsinghua University,CVPR 2020
- Reference
Adversarial Multimodal Representation Learning for Click-Through Rate Prediction — WWW 2020, Alibaba Group
Motivation
现有的多模态学习方法,在利用不同模态信息时,一般是简单的拼接不同模态的信息或是使用注意力机制分配不同模态的权重。然而,这些方法均忽略了来自不同模态信息的冗余性问题,导致他们学习到的多模态表示没有很好的反应不同模态的重要性。因此,作者提出了一个针对 CTR 任务的多模对抗表示网络模型(Multimodal Adversarial Representation Network,MARN),通过探索 modality-specific 和 modality-invariant 特征来解决冗余性问题。
Method
作者核心思想是,对于出现在特定模态内的特征(modality-specific features),可以动态的计算来自不同模态的特征重要性权重,而对于非特定模态的特征(modality-invariant features)应当作为补充信息固定其重要性权重,这样达到解决冗余性问题。以下图为例,商品标题为 “粉色裙子”,那么 “纱质” 在就是来自图像模态中的 modality-specific 特征,应当动态学习其重要性权重;而 “粉色” 同时出现在标题和图片中,对应 modality-invariant 特征,应当固定其重要性权重避免冗余。

Fig. 1. 淘宝商品展示图. (Image source: inews)
基于上述思想,MARN 模型框架如下图所示,通过 Multimodal Attention Network 来学习来自不同模态的 modality-specific 特征权重,通过 Multimodal Adversarial Network 学习跨模态 modality-invariant 特征表示。在应用到 CTR 任务上时,\(\mathcal{X}\) 表示候选商品,\(x_i\) 是用户行为序列中的商品。
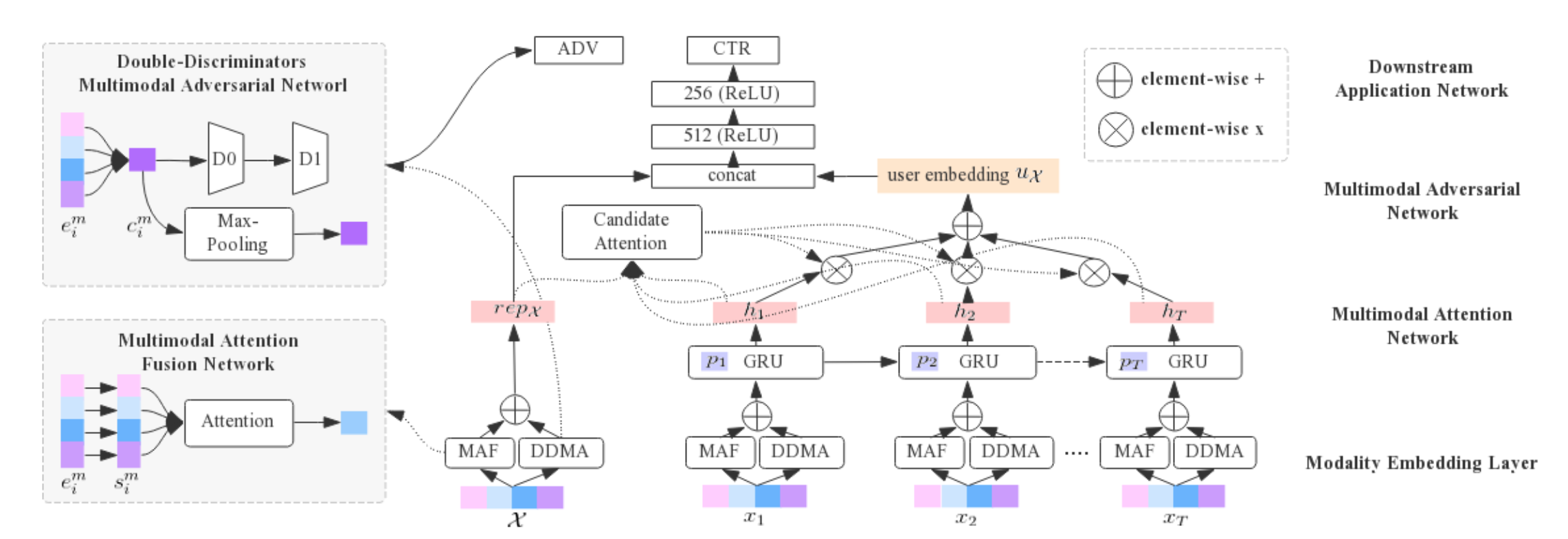
Fig. 2. MARN整体框架示意图. (Image source: X Li et al.)
1. Modality Embedding Layer
该层主要得到用户行为序列中,商品的多模态嵌入表示和对应的用户行为嵌入表示,给定输入商品行为对 <\(x_i\), \(p_i\)>,\(x_i\)将会得到四个模态的嵌入信息,包括 IDs、image、title 和 statistics。
-
IDs 主要包含 item_id、brand_id 等,表示为 \([x_i^{id(1)},...,x_i^{id(F)}]\) 对应 F 个 id 特征,每个 id 用一个 one-hot 向量表示,随后经过 embedding-lookup table 得到 IDs 的嵌入表示 \(e_i^{id}\);
- image 主要是通过预训练的 VGG16 提取 4096 维的向量;
- title 包含多个单词,使用 CNN 模型提取词向量,得到一个 \(h\times d\) 的矩阵表示,\(h,d\) 分别表示单词数和词向量嵌入维度;
- statistics 主要是商品的历史曝光、点击等信息,这里通过离散化等手段最终得到两个 8 维的向量
用户行为 \(p_i\) 则包含了行为类型和行为时间等信息,同样通过嵌入得到其嵌入表示 \(e_i^{p}\)。
2. Multimodal Attention Network
作者指出现有模型在利用不同模态信息时存在的冗余问题,本质上可以理解为 modality-specific 特征的分布是独立的,而 modality-invariant 特征的分布则是很接近的。因此可以考虑将商品的嵌入表示 \(e_i^{m}\) 分解为两个 256 维的 modality-specific 表示 \(s_i^m\) 和 modality-invariant 表示 \(c_i^m\):
\[s_i^m,c_i^m= S_m(e_i^m),I(e_i^m)\] 其中,\(S_m(\cdot)\) 独立于不同的模态 \(m\),\(I(\cdot)\) 则由所有模态共享。随后通过如下图所示的多模注意力融合网络来学习 modality-specific 特征的重要性权重并得到最终的加权表示 \(s_i\):
\[\begin{aligned} s_{i} &=\sum_{m=1}^{M} \operatorname{atten}_{i}^{m} \odot s_{i}^{m} \\ \operatorname{atten}_{i}^{m} &=\tanh \left(W_{m}^{\top} \cdot s_{i}^{m}+b_{m}\right) \end{aligned}\]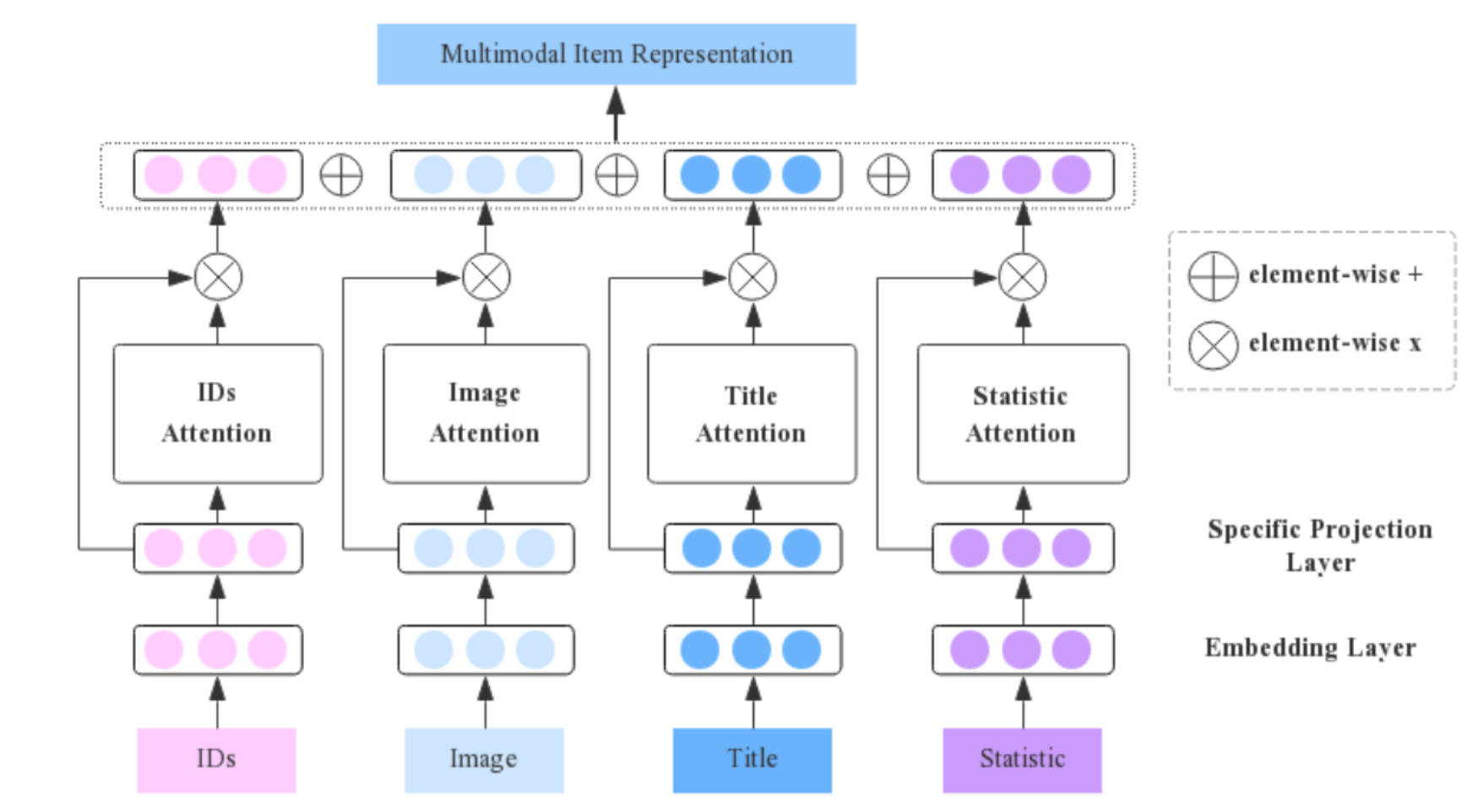
Fig. 3. Multimodal Attention Fusion Network. (Image source: X Li et al.)
3. Multimodal Adversarial Network
作者表示仅仅通过带标签的监督训练,是无法保证由 \(S_m(\cdot)\) 和 \(I(\cdot)\) 提取出理想的 modality-specific 和 modality-invariant 特征的。可以通过对抗训练,使得 \(S_m(\cdot)\) 提取的不同模态的 modality-specific 分布尽可能远离,而通过 \(I(\cdot)\) 提取的 modality-invariant 分布尽可能接近。
-
Double-Discriminators Multimodal Adversarial(DDMA):
作者提出的 DDMA 网络有两个贡献:以往的多模态对抗训练一般是 one-vs-one 的,在这里拓展跨模态对抗训练到更多的模态;使用两个判别器,第一个判别器的目标是识别 modality-invariant 特征,并增强识别的 modality-invariant 特征以迷惑第二个判别器,与此同时第二个判别器会驱动跨模态知识迁移,从而更好的学习多模态公共子空间,以获取最终的 modality-invariant 特征。
如下图所示,对于第一个判别器 \(D_0\),对应一个 M-class 的分类器最小化 M 个模态之间的 JS 散度,其输入为经过 Invariant 映射层 \(I(\cdot)\) 后得到的 modality-invariant 特征 \(x = c=I(e)\)。现在假设经过训练后判别器 \(D_0\) 达到最优状态且输入 \(x\) 属于模态 \(i\),此时最优判别器 \(D_0^i(x)\) 代表输入 \(x\) 关于模态 \(i\) 的似然概率,即如果 \(D_0^i(x)\approx1\),可以认为此时 \(x\) 具有最少的跨模态公共特征,作者使用 \(w^i(x)=1-D^*_0(x)\) 来表示其对于最终的 modality-invariant 特征的贡献度,\(D_0^i(x)\) 越高意味着其包含的公共特征越少,对 modality-invariant 特征贡献也就越小。
第二个判别器 \(D_1\) 同样也是一个 M-class 的分类器最小化模态之间的 JS 散度,此时第一个判别器得到的 \(w^i(x)\) 会作为增强 modality-invariant 特征的权重对 \(D_0\) 的输出进行增强后输入到 \(D_1\) 中,进行对抗训练。简单来说,判别器 \(D_0\) 用于识别 modality-invariant 特征并得到的贡献度,判别器 \(D_1\) 则根据 \(D_0\) 得到的贡献度,用于更好的完成模态间知识迁移得到最终的 modality-invariant 特征 \(c_i\)。
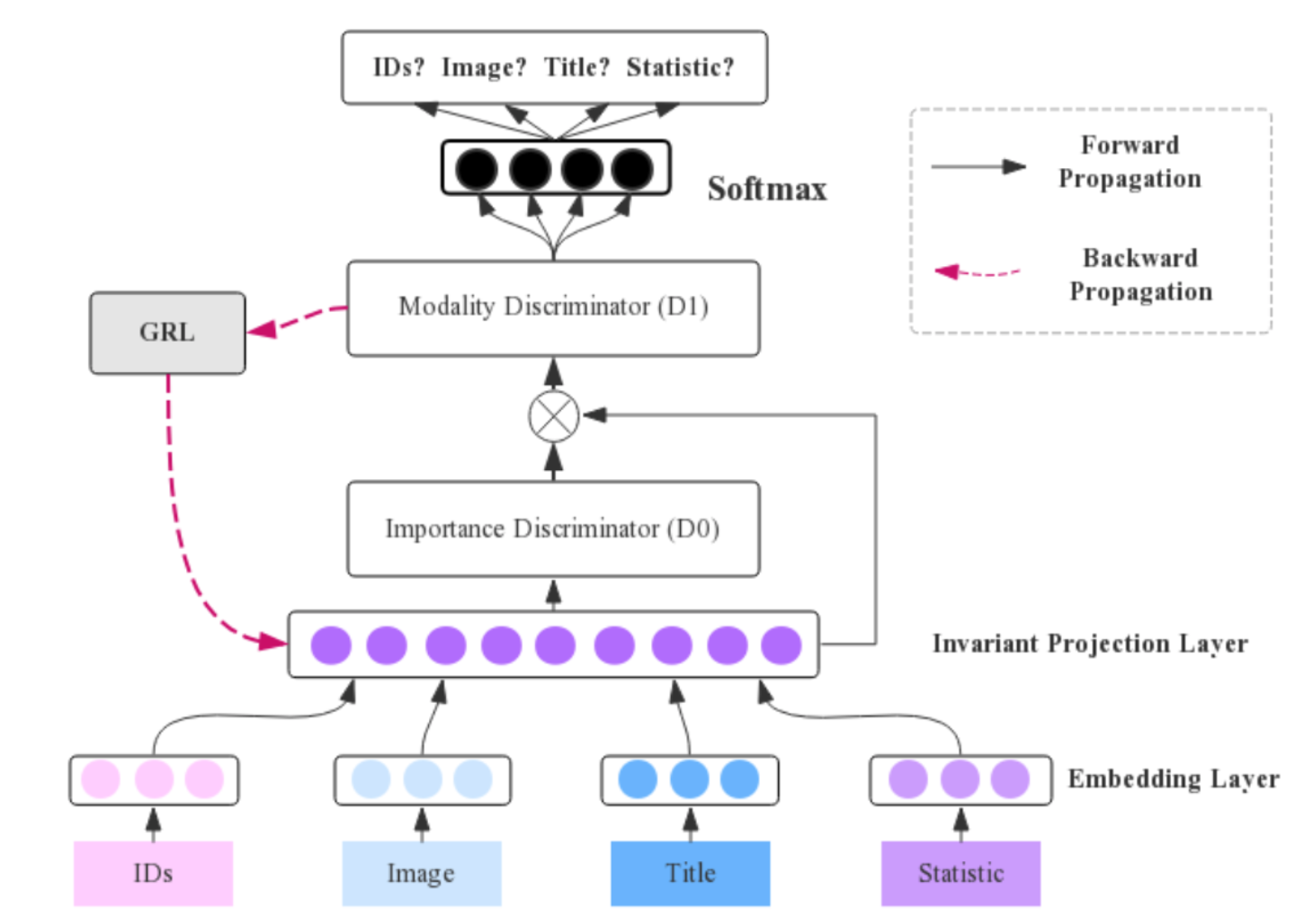
Fig. 4. Double-Discriminators Multimodal Adversarial(DDMA). (Image source: X Li et al.)
-
Modality-Specific Discriminator:
DDMA 的作用是最小化不同模态之间的 modality-invariant 特征分布差异以学习到一个更好的 modality-invariant 特征,而为了得到一个更好的 modality-specific 特征,需要最大化不同模态之间的 modality-specific 特征的分布差异,这里通过一个参数共享于判别器 \(D_1\) 的判别器 \(D_s\) 实现,最终得到 modality-specific 特征 \(s_i\),模型最后的多模态商品表示 \(rep_i = s_i + c_i\)。
4. Downstream Application Network
在应用到下游任务 CTR 中时,根据上述结构,对于用户序列中的每个商品通过多模注意力网络进行多模特征融合(MAF)提取 modality-specific 特征,并通过 DDMA 提取 modality-invariant 特征,随后输入到一个基于 Attention 改进的 GRU 模型 APGRU 学习用户嵌入表示,最后和候选商品嵌入表示拼接后通过 MLP 得到点击率预估值。
InterBERT: Vision-and-Language Interaction for Multi-modal Pretraining — KDD 2020 在投,Alibaba
Motivation
作者指出,现有的多模态预训练模型,存在两方面问题:一是预训练任务比较简单,例如 masked language/Object modeling 任务以及 image-text matching 任务;二是 single-stream 类模型例如 Unicoder-VL (见下图1)仅仅是用 BERT 模型来融合两个模态的信息,而 two-stream 类模型例如 ViLBERT、LXMERT (见下图2、3)仅仅通过 co-attention 融合各个 stream 的信息,缺乏 stream 内的 self-attention(原文:where there is no self attention to the self-context in each stream in the co-attention layers)。基于上述,作者提出 InterBERT,包含一个 single-stream cross-modal encoder 除了各个模态的输入,并使用 two-stream encoder 分别处理不同模态的信息,以最大程度的进行模态间信息交互同时保留各个模态的独立性信息。另外,作者还提供了一个基于淘宝的 3.1M 大小的中文 image-text 多模态预训练数据集。
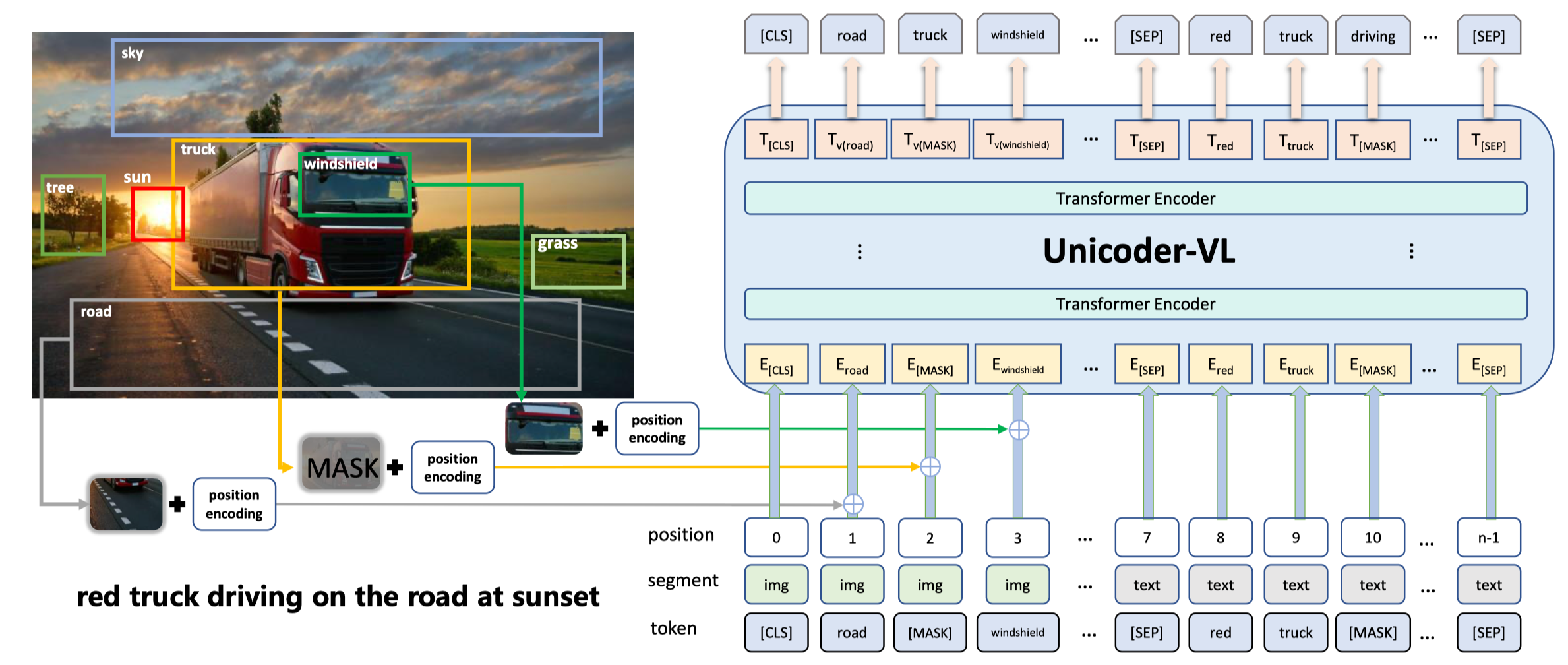
Fig. 1. Unicoder-VL 框架示意图. (Image source: G Li et al.)
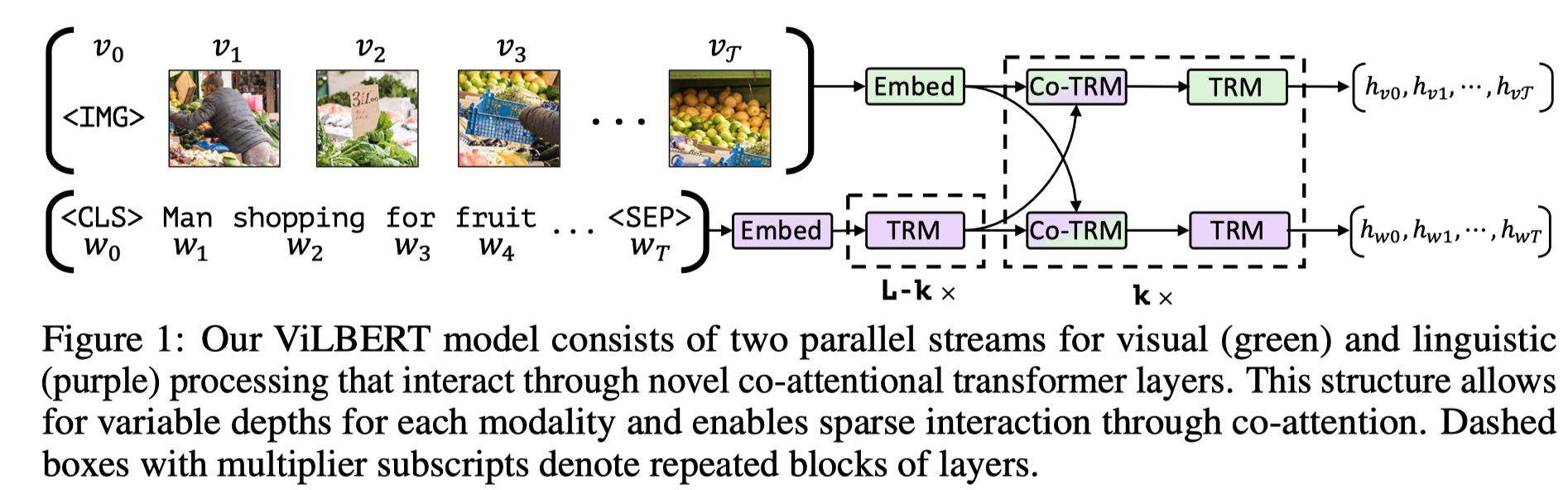
Fig. 2. ViLBERT 框架示意图. (Image source: J Lu et al.)
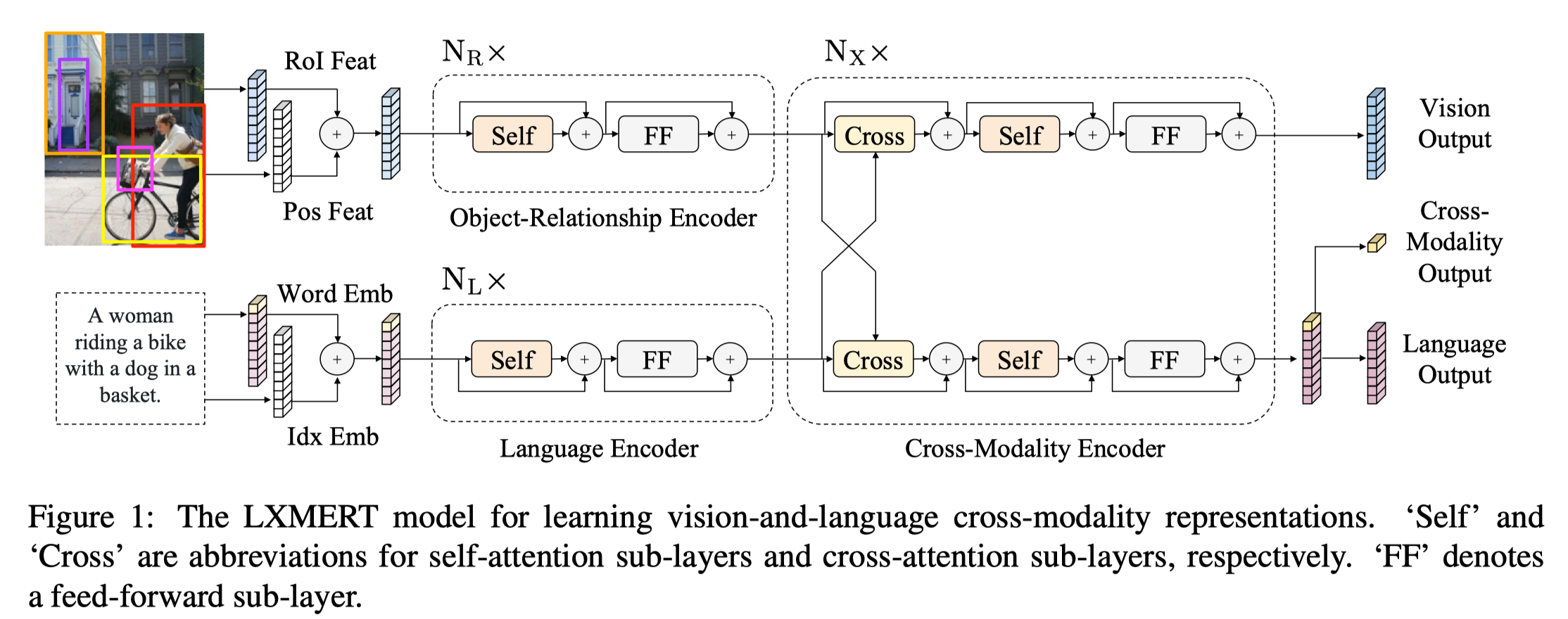
Fig. 3. LXMERT 框架示意图. (Image source: H Tan et al.)
Method
1. 模型概览
InterBERT 模型框架图如下图所示,主要包括 Image Embedding、Text Embedding、Single-Stream Interaction Module 以及 Two-Stream Independence Module。
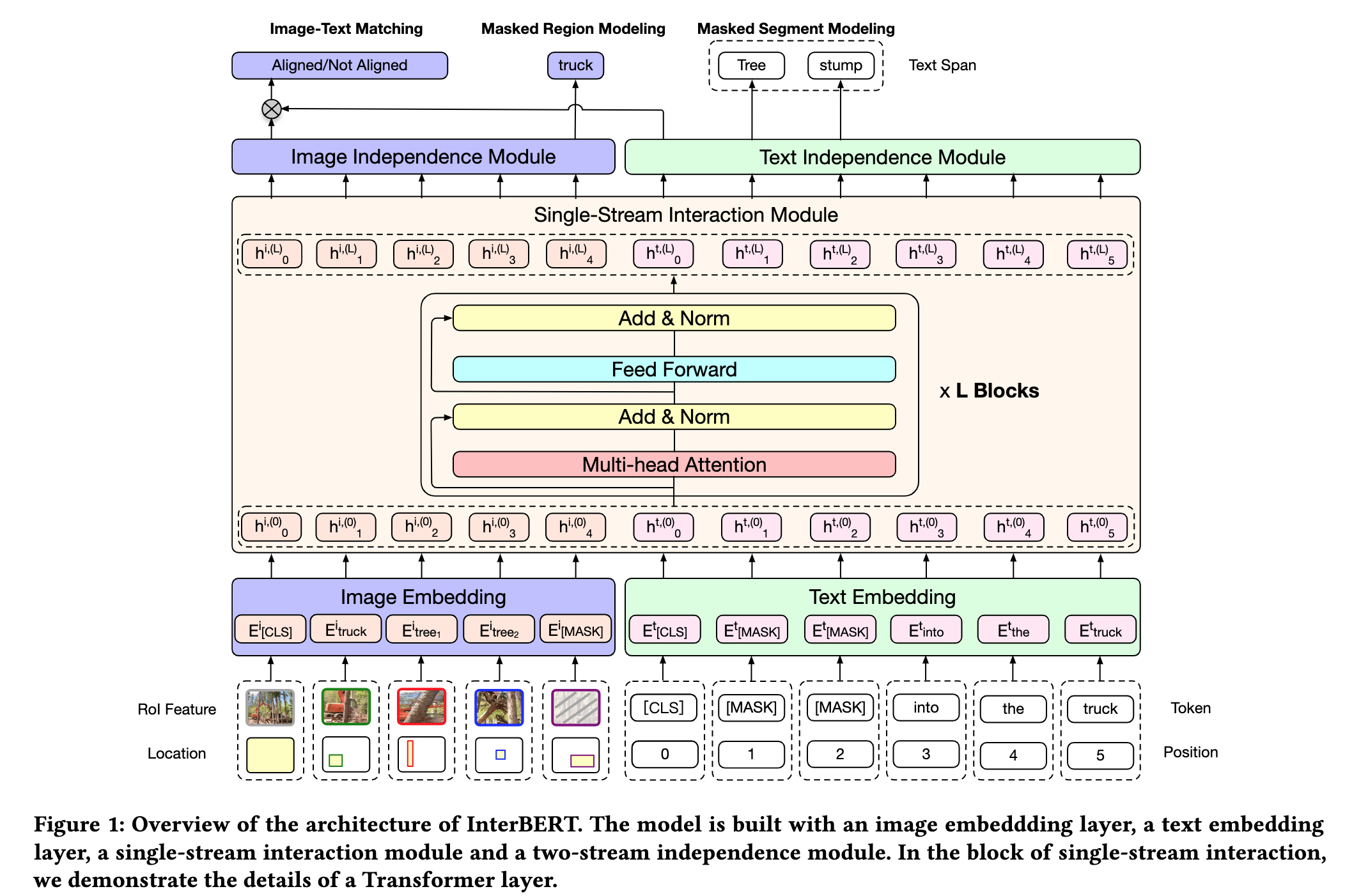
Fig. 4. InterBERT 框架示意图. (Image source: J Lin et al.)
-
Text Embedding:与 BERT 类似,采用 WordPiece 方法进行文本 tokenization,另外不同于 BERT 的地方有:在 mask 文本时并非完全随机,而是 mask 平均长度为 3 的连续文本字段;采用 MLP 学习 position embedding,并和 word embedding 相加输入到归一化层(LN Layer)中;
-
Image Embedding:使用 Faster-RCNN 提取图片中 RoI 对象来序列化图片,同时以 RoI 的回归边框 bbox 作为位置信息,同样 bbox 位置信息会通过 MLP 提取得到 position embedding 并和 RoI 特征相加输入到 LN 层中;
-
Single-Stream Interaction Module:基于 Transformer 实现,但这里作者使用了 GeLU 激活函数,一个完整的 BERT layer 包括:
\[\begin{array}{l}h^{l}=\text { MultiheadAttention }\left(x^{l-1}\right) \\\tilde{h}^{l}=\text { LayerNorm }\left(x^{l-1}+h^{l}\right) \\\hat{h}^{l}=W_{2}\left[\operatorname{GeLU} \left(W_{1} \tilde{h}^{l}+b_{1}\right)\right]+b_{2} \\x^{l}=\text { LayerNorm }\left(\tilde{h}^{l}+\hat{h}^{l}\right)\end{array}\]作者认为,这种结构可以很好的进行模态间信息交互,相比于只能使用其他模态信息计算 co-attention 的模型(如上图 3 的 LXMERT),其在交互过程中结合了模态内的 self-attention 和模态间的 co-attention,因此可以生成更好的上下文相关的表示。
-
Two-Stream Independence Module:除了通过 Single-Stream Interaction Module 进行模态间信息融合,为了保留模态内的独立信息,作者为每个模态单独设计了一个 Transformer 结构来完成这一任务。
2. 预训练任务
- Masked Segment Modeling:按照 10% 的概率挑选文本 mask 的锚点,随后以锚点开始 mask 连续的单词,平均长度为3,最后预测被 mask 的单词。
- Masked Region Modeling:按照 15% 的概率挑选图像 RoI mask 的锚点,随后将被选中的 RoI 以及与该 RoI 重叠 IOU 值大于 0.4 的 RoIs 一起 mask 为全 0 向量,预测被 mask 的 RoI 类别。
- Image-Text Matching:首先在模型整体框架之上再次构建一个 MLP,将两个模态最后的输出相乘输入到 MLP 中得到最后的 matching score。
IMRAM: Iterative Matching with Recurrent Attention Memory for Cross-Modal Image-Text Retrieval — Tsinghua & Kwai, CVPR 2020
Motivation
现有的模态融合方法,使用注意力机制捕捉图像和文本的对应关系,但是它们往往认为不同模态的信息语义等价,因此无论模态信息的复杂度如何,都是进行统一对齐。作者认为,不同模态的语义具有多样性,例如人类在观察图像和文本是否匹配时,一般从低层语义开始先看图片中的对象和文本中的名词,而后重新审视图像和文本来挖掘对象之间的关系,而现有的方法使用的简单的融合框架很难捕捉模态间复杂的对应关系。因此作者提出具有多步对齐(multi-step alignment)的 IMRAM 模型,IMRAM 通过迭代匹配机制捕捉图像和文本之间的细粒度对应关系,并通过记忆蒸馏(memory distillation)来提炼较早的 step 中的对齐知识指导后续 step 的学习。
Method
IMRAM 框架示意图如下图所示。
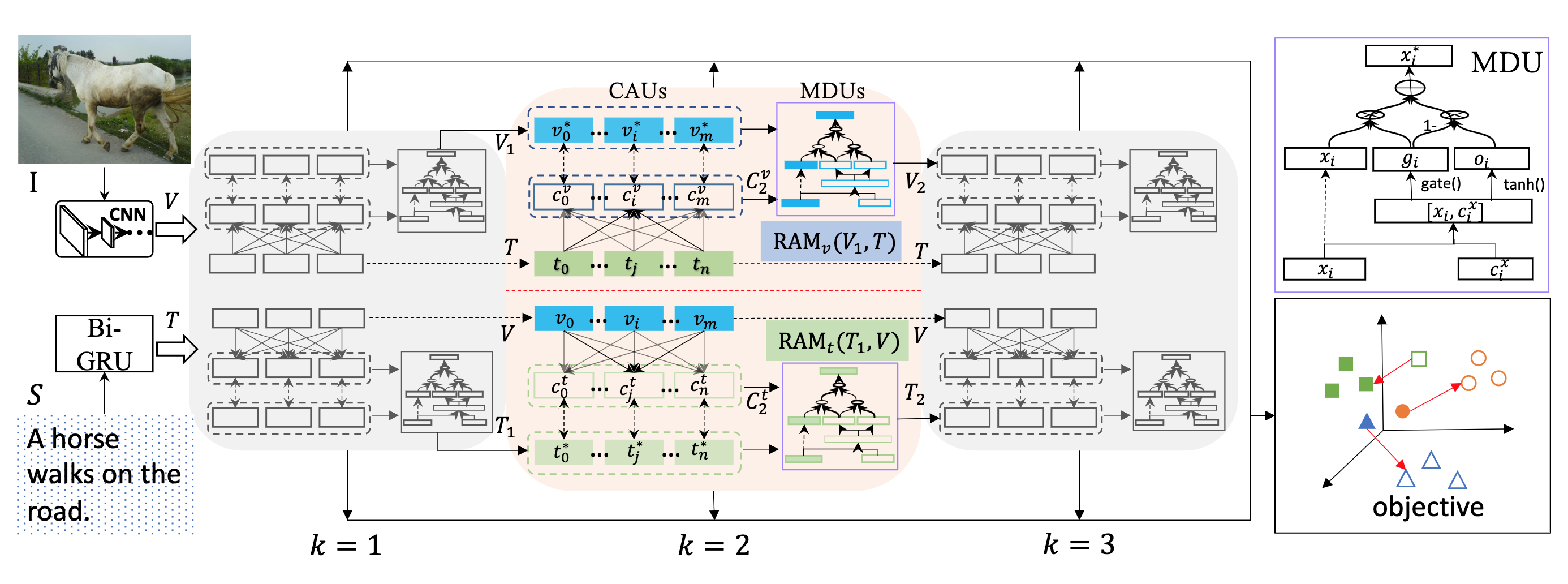
Fig. 1. IMRAM 框架示意图. (Image source: H Chen et al.)
1. Cross-Modal Featrue Representation
-
Image Representation: 通过预训练的 Faster-RCNN 提取 RoI 的特征向量 \(f_i\),随后通过线性变换为特征向量 \(v_i\),随后对向量进行归一化,得到最终图像表示 \(V = \{v_i|i=1,2,...,m,\ v_i \in \mathbb{R}^d\}\)。
-
Text Representation: 使用 Bi-GRU 提取单词表示 ,取前向和后向的单词表示均值作为最终的单词向量表示,并归一化得到最终文本表示 \(T = \{t_j|j=1,2,...,n,\ t_j \in \mathbb{R}^d\}\)。
2. RAM:Recurrent Attention Memory RAM 模块以循环提炼之前的对齐知识的方式,在嵌入空间内完成片段对齐。RAM 有两个输入,其中查询 \(X=\{x_i|i\in[1,m'],\ x_i\in\mathbb{R}^d\}\) ,响应 \(Y=\{y_j|j\in[1,n'],\ y_j\in\mathbb{R}^d\}\),查询和响应对应 \(V,T\) 或是 \(T,V\)。
-
Cross-modal Attention Unit(CAU): CAU 单元的作用是总结上下文信息,首先计算 \(X\) 和 \(Y\) 中特征 \(x_i\) 和 \(y_j\) 的相似度得到 \(z_{ij}\),随后计算 \(x_i\) 关于相应 \(Y\) 的注意力加权:
\[c_{i}^{x}=\sum_{j=1}^{n^{\prime}} \alpha_{i j} y_{j}, \quad \text { s.t. } \quad \alpha_{i j}=\frac{\exp \left(\lambda \bar{z}_{i j}\right)}{\sum_{j=1}^{n^{\prime}} \exp \left(\lambda \bar{z}_{i j}\right)}\]
最后得到 \(X\)-grounded 对齐特征 \(C^x = \{c_i^x|i\in[1,m'],\ c_i^x\in\mathbb{R}^d\}\)。
-
Memory Distillation Unit(MDU): 为了提炼对齐知识用于下一次的对齐操作,MDU 单元采用记忆蒸馏的方法来更新查询 \(X\),具体方法是聚合 \(X\)-grounded 特征和 \(X\):
\[x_i^* = f(x_i, c_i^x)\]聚合函数 \(f\) 可以是加性层、MLP 等,作者使用门控机制:
\[\begin{aligned} {g}_{i} &=\operatorname{gate}\left(W_{g}\left[{x}_{i}, {c}_{i}^{x}\right]+b_{g}\right) \\ {o}_{i} &=\tanh \left(W_{o}\left[{x}_{i}, {c}_{i}^{x}\right]+b_{o}\right) \\ {x}_{i}^{*} &={g}_{i} * {x}_{i}+\left(1-{g}_{i}\right) * {o}_{i} \end{aligned}\] -
RAM block:组合 CAU 和 MDU 构建成 RAM block,表示为:
3. Iterative Matching with RAM
这部分主要是如何迭代的利用 RAM 模块学习的记忆信息,首先给定输入的图像和文本 \(I、S\),使用两个独立的 RAM block 得到:
\[\begin{array}{l} {C}_{k}^{v}, {V}_{k}=\mathbf{R} \mathbf{A} \mathbf{M}_{v}\left({V}_{k-1}, {T}\right) \\ {C}_{k}^{t}, {T}_{k}=\mathbf{R} \mathbf{A} \mathbf{M}_{t}\left({T}_{k-1}, {V}\right) \end{array}\]其中,\(V_0=V,\ T_0=T\),而 \(k\) 表示迭代所处的 step,每个 step,都可以计算得到 matching score:
\[F_{k}({I}, {S})=\frac{1}{m} \sum_{i=1}^{m} F_{k}\left({r}_{i}, {S}\right)+\frac{1}{n} \sum_{j=1}^{n} F_{k}\left({I}, {w}_{j}\right)\]其中,\(F_k(r_i, S)\) 和 \(F_k(I,w_j)\) 分别表示 region-based 和 word-based matching score:
\[\begin{array}{l} F_{k}\left({r}_{i}, {S}\right)=\operatorname{sim}\left({v}_{i}, {c}_{k i}^{v}\right) \\ F_{k}\left({I}, {w}_{j}\right)=\operatorname{sim}\left({c}_{k j}^{t}, {t}_{j}\right) \end{array}\]经过 \(K\) 个 step 之后,最终得到 matching score 为所有 step 的和。
Fine-grained Video-Text Retrieval with Hierarchical Graph Reasoning — Renmin University of China,CVPR 2020
Motivation
多模态学习的方法一般是学习一个联合的嵌入表示,这种方式不足以表达复杂的场景、对象以及行为等之间的复杂关系;与此同时, 现有的 video-text 匹配方法采取类似 image-text 匹配的方法以序列化的方式学习 frame 与 words 之间的关系再进行对齐,这种方法在 image-text 中效果不错,但在 video-text 匹配中由于 video 和 text 的 pair 对之间监督关系更弱因此效果不佳。为了更好地进行细粒度的 video-text 检索,作者提出分层图推理 (Hierarchical Graph Resoning,HGR) 模型,将 video-text 匹配问题转换到 global-to-local 层次,如下图所示,通过分解为 events、actions 以及 entities 三个层次进行。
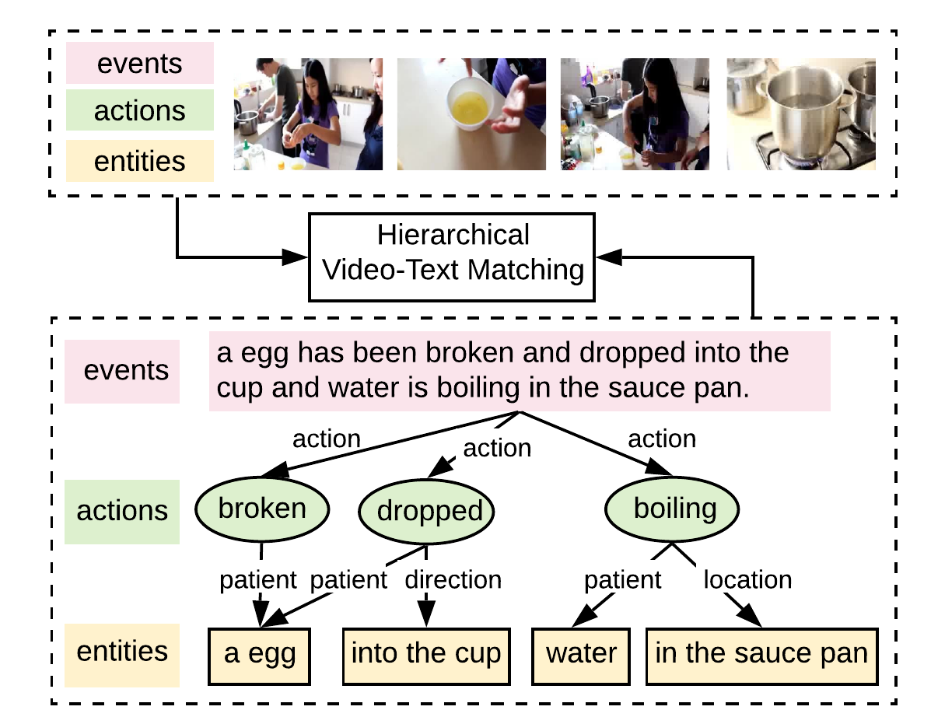
Fig. 1. 分层图推理(Hierarchical Graph Resoning, HGR). (Image source: S Chen et al.)
Method
如下图所示,HGR 模型主要包含三个模块:hierarchical textual encoding、hierarchical video encoding 以及 video-text matching。
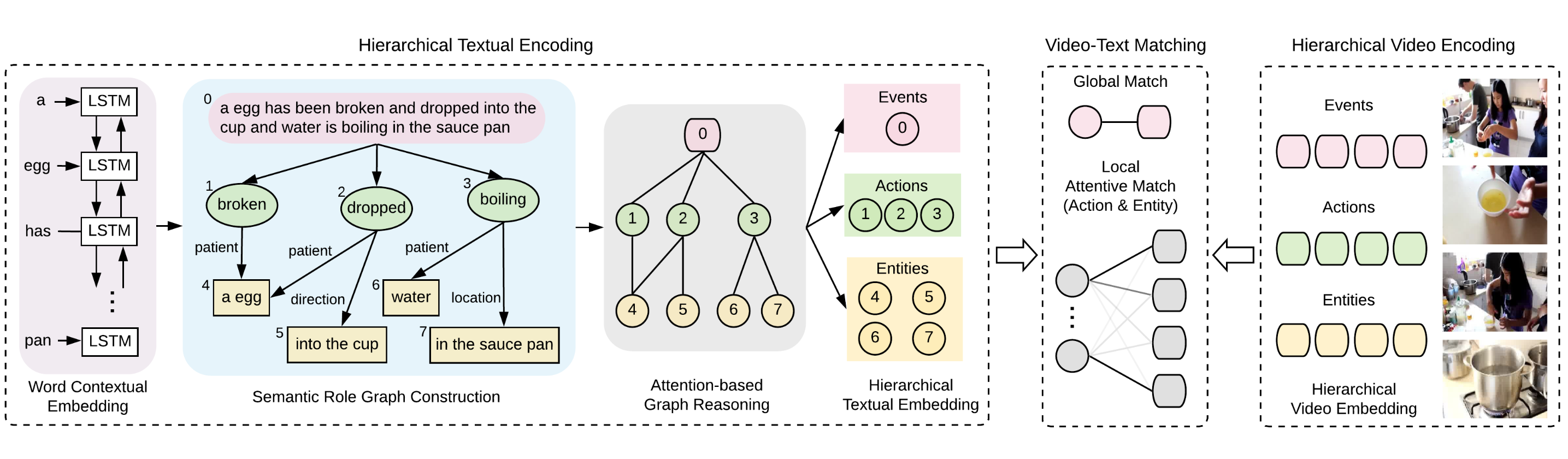
Fig. 2. HGR的三个主要模块. (Image source: S Chen et al.)
1. hierarchical textual encoding
此模块的主要作用是从描述文本中构建 global-to-local 的分层文本表示。
-
Semantic Role Graph Structure:给定视频的文本描述 \(C=\{c_1, c_2, ..., c_N\}\),\(C\) 首先会作为 event 节点,随后使用语义角色分析工具1 获取 \(C\) 中的动词、名词以及名词在对应的动词中扮演的语义角色信息(角色类型详见下表)。动词会被视为 action 节点并和 event 节点通过有向边连接,名词会被视为 entity节点,一个语义角色图的构建如上图左部所示。
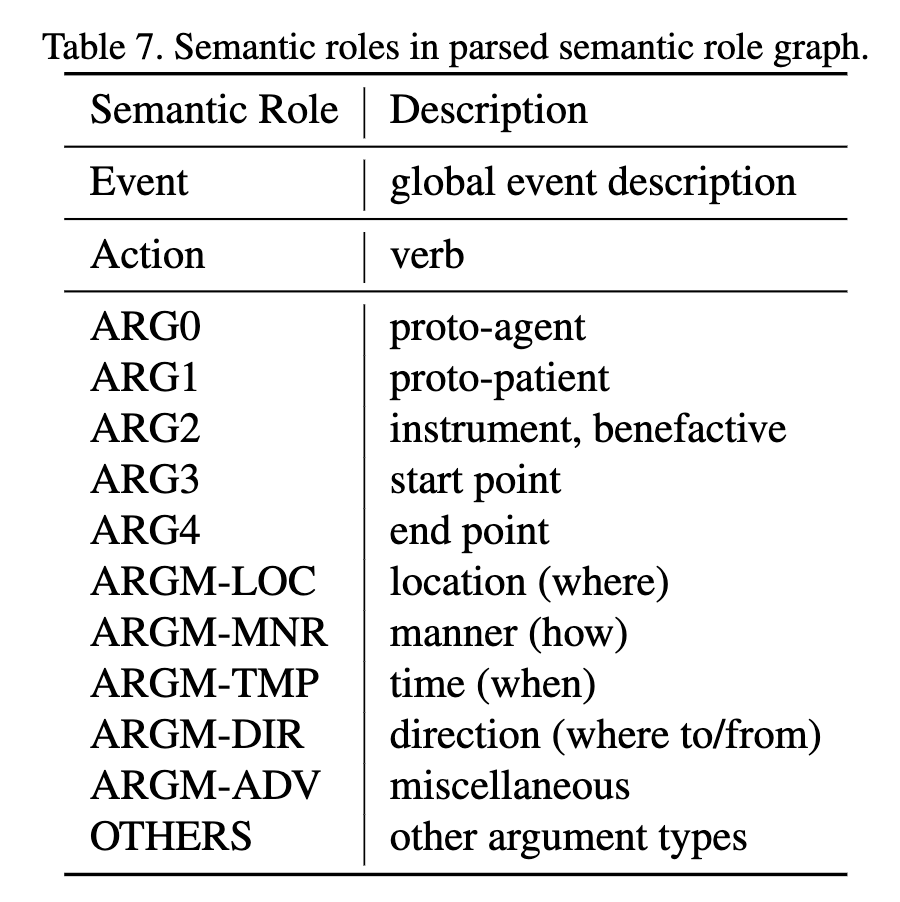
Fig. 3. 语义角色构建. (Image source: S Chen et al.)
-
Initial Graph Node Representation:此部分初始化不同类型节点的嵌入表示,对于 event 节点首先通过 Bi-LSTM 学习每个单词的表示 \(w_i\),随后使用注意力加权得到 global event embedding 表示 \(g_e\):
\[g_{e} =\sum_{i=1}^{N} \alpha_{e, i} w_{i} ,\ \ \ \ \alpha_{e, i} =\frac{\exp \left(W_{e} w_{i}\right)}{\sum_{j=1}^{N} \exp \left(W_{e} w_{j}\right)}\]对于 action 和 entity 节点,对每个节点内的单词进行 maxpooling 得到最后的 action 节点表示 \(g_a = \{g_{a,1},g_{a,2},...,g_{a,N_a}\}\) 和 entity 表示 \(g_o = \{g_{o,1},g_{o,2},...,g_{o,N_o} \}\)。
-
Attention-based Graph Reasoning:在进行图推理的时可以直接应用图卷积网络 GCN 模型,但是直接应用 GCN 存在参数较多问题。因此,作者分解参数为两部分:一个共享于所有边类型的特征变换矩阵 \(W_t \in \mathbb{R}^{D\times D}\) 以及一个仅用于不同语义角色的角色嵌入矩阵 \(W_r \in \mathbb{R}^{D\times K}\),\(D,K\) 分别为节点表示的维度以及语义角色个数。对于 GCN 的第一层,首先将不同类型节点嵌入 \(g_i \in \{g_e, g_a, g_o\}\) 乘以它们对应的语义角色:
\[g_{i}^{0}=g_{i} \odot W_{r} r_{i j}\]其中,\(r_{ij}\) 表示节点 \(i\) 和 \(j\) 之间的语义角色 one-hot 向量表示。现在假设 \(g_i^l\) 表示节点 \(i\) 通过 GCN 的第 \(l\) 层后的输出,此时再通过图注意力网络 GAT 模型来选择相关的邻居节点以增强节点表示:
\[\tilde{\beta}_{i j} =\left(W_{a}^{q} g_{i}^{l}\right)^{T}\left(W_{a}^{k} g_{j}^{l}\right) / \sqrt{D} ,\ \ \ \ \ \ \ \beta_{i j} =\frac{\exp \left(\tilde{\beta}_{i j}\right)}{\sum_{j \in \mathcal{N}_{i}} \exp \left(\tilde{\beta}_{i j}\right)}\]其中,\(\mathcal{N}_i\) 表示节点 \(i\) 的邻节点,\(W_a^q,W_a^k\) 分别表示用于计算注意力的权重矩阵。随后再结合共享 的特征变换矩阵 \(W_t\) 使用残差结构得到第 \(l+1\) 层的节点表示 \(g_i^{l+1}\):
\[g_{i}^{l+1}=g_{i}^{l}+W_{t}^{l+1} \sum_{j \in \mathcal{N}_{i}}\left(\beta_{i j} g_{j}^{l}\right)\]最终,经过 \(l\) 个 GCN 层之后,得到最后的 event、action 以及 entity 表示 \(c_e, c_a, c_o\)。
2. hierarchical video encoding
视频很难构建直观意义上的分层结构,因此作者直接学习三个不同的视频嵌入表示替代层次表示。具体的,对于输入的视频 \(V=\{f_1, f_2,...,f_M\}\),使用三个不同的变换矩阵 \(W_e^v, W_a^v, W_o^v\) 得到三个视频嵌入表示:
\[v_{x,i} = W_x^vf_i, \ \ \ \ x\in\{e,a,o\}\]对应 global event 的嵌入表示 \(v_e\) 通过各帧特征采用注意力加权得到,对应 action 和 entity 层次的视频表示则为逐帧的表示即 \(v_a = \{v_{a,1},v_{a,2},...,v_{a,M}\}\) 以及 \(v_o = \{v_{o,1},v_{o,2},...,v_{o,M}\}\)。
3. video-text matching
在进行匹配计算时,将会聚合不同层次的信息。
- Global Matching:对于 global event 层次,直接计算文本和视频的 global 表示的余弦得分:\(s_e = cos(v_e, c_e)\)
-
Local Attentive Matching:对于 action 和 entity 层次,首先计算每对跨模态局部文本片段与视频帧组合的相似性得分:
\[s_{ij}^x= cos(v_{x,j},c_{x,i}),\ \ \ \ \ x \in \{a, o\}\] \(s_{ij}^x\) 表达的含义为,文本中的局部片段 \(i\) 和视频中某个帧 \(j\) 之间的相关度,随后再对 \(s_{ij}^x\) 进行 stack attention2操作以进行归一化:
\[\varphi_{i j}^{x}=\operatorname{softmax}\left(\lambda\left(\left[s_{i j}^{x}\right]_{+}/ \sqrt{\sum_{j}\left[s_{i j}^{x}\right]_{+}^{2}}\right)\right)\] 其中,\([\cdot]_{+} = max(\cdot,0)\)。\(\varphi_{i j}^{x}\) 将会用于作为注意力权重动态的对齐文本局部片段和视频帧,得到文 本片段关于视频的加权相似性得分 \(s_{x,i}=\sum_j{\varphi_{i j}^{x}s_{ij}^x}\),最后叠加所有的 \(s_{x,i}\) 得到 action、entity 层 次的相似性匹配得分 \(s_x=\sum_i{s_{x,i}},\ x\in\{a,o\}\)。
Graph Structured Network for Image-Text Matching —Chinese Academy of Sciences,CVPR 2020
Motivation
现有的 Image-Text 匹配方法基本上都是学习粗糙的图文对应关系,即基于图片中对象的共现对应关系(如下图左部所示),因而缺乏细粒度的词组对应关系(如下图右部所示),这种现象会导致模型难以正确的学习对应关系,例如在粗粒度下 “dog” 和图片中的狗产生交叉对应。因此,作者提出图结构化匹配网络(Graph Structured Matching Network,GSMN)将对象、关系以及属性建模为结构化短语以学习细粒度的对应关系(如下图中下部所示)。
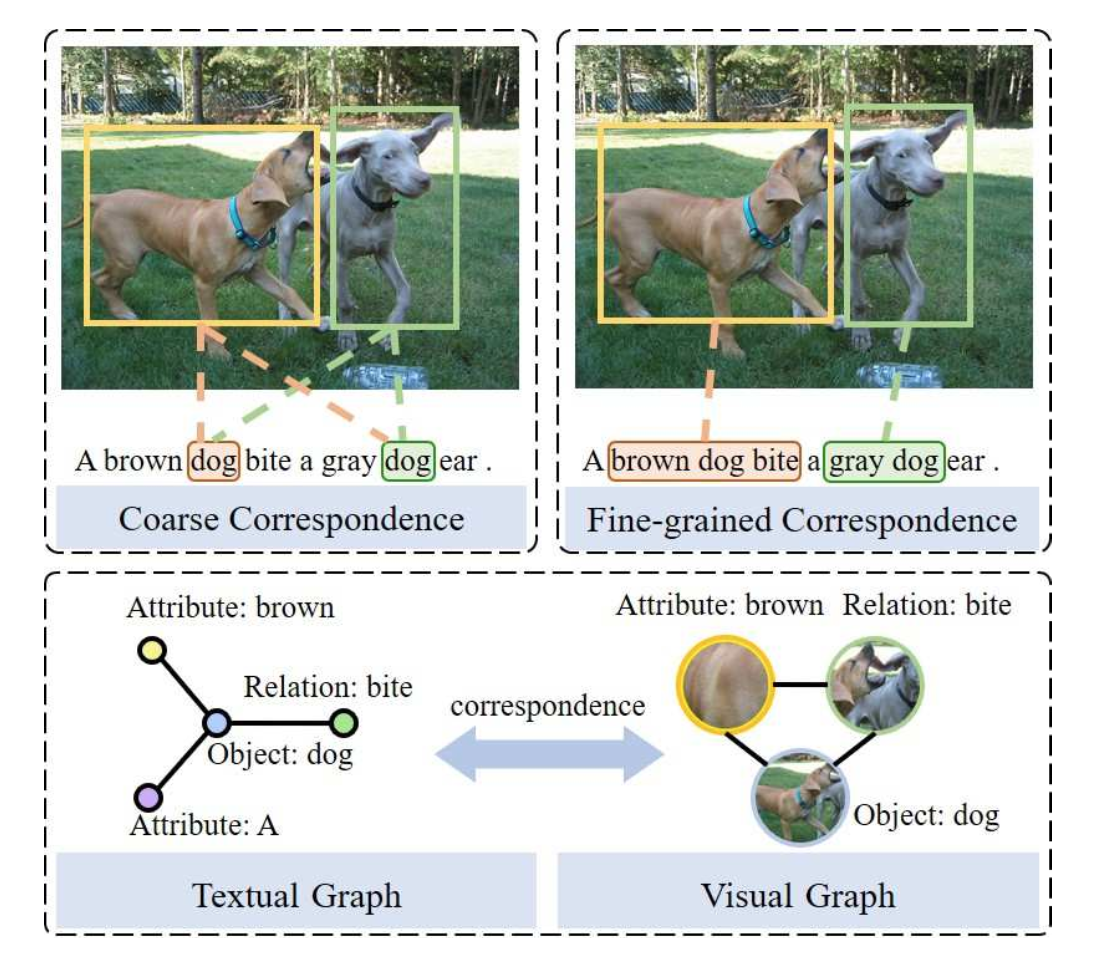
Fig. 1. 细粒度对应关系. (Image source: C Liu et al.)
Method
GSMN 的框架图如下图所示,主要分为三大模块:特征表示模块(Feature Representation)、图构建模块(Graph Construction) 以及多模图匹配模块(Multimodal Graph Matching),其中多模图匹配模块具体分为 Node-level 和 Structure-level 匹配。
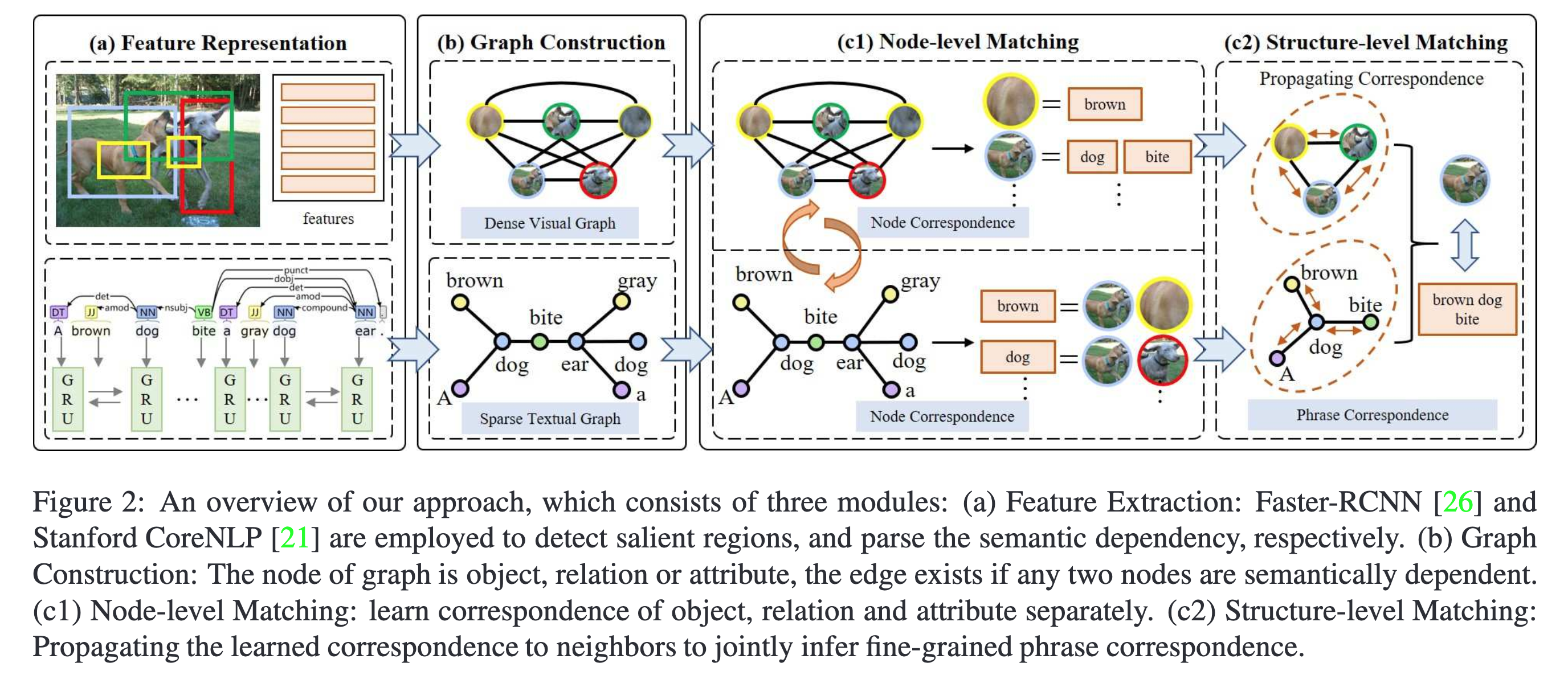
Fig. 2. GSMN框架示意图. (Image source: C Liu et al.)
1. Feature Representation
- Visual Representation: 通过预训练的 Faster-RCNN 提取图像 \(I\) 的 \(n\) 个 region,并输入到预训练的 ResNet-101 中提取 region 的特征表示,最后通过全连接层变换特征维度得到图像表示为 \(\{v_1,v_2,...,v_n\}\)。
- Textual Representation: 通过 Bi-GRU 提取文本 \(T\) 中的 \(m\) 个单词表示,取前后向单词嵌入表示的均值,最终得到文本表示 \(\{u_1,u_2,...,u_m\}\)。
2. Graph Construction
-
Textual Graph:构建的文本图表示为 \(G_1 = (V_1,E_1)\),\( G_1\) 是一个稀疏图,其邻接矩阵 \(A\) 含有自循环(对角值置1),其边权重矩阵为 \(W_e\) 表示节点之间的语义依赖性。
为了构建 \(G_1\),首先通过 Stanford 开源工具 CoreNLP 解析出文本中的对象(名词)、关系(动词)以及属性(形容词或量词),同时还可以解析出他们之间的语义依赖关系。例如 “A brown dog bite a gray dog ear” 中 “A”、”brown” 就是第一个 “dog” 对象的属性,”bite” 则是关系。通过这种方式将每个单词表示为一个节点,它们之间的边就是它们的语义依赖关系,则可以结算相似性矩阵 \(S\),其中的元素 \(s_{ij}\) 表示第 \(i\) 个节点和第 \(j\) 个节点之间的相似性:
\[s_{i j}=\frac{\exp \left(\lambda u_{i}^{T} u_{j}\right)}{\sum_{j=0}^{m} \exp \left(\lambda u_{i}^{T} u_{j}\right)}\]则边权重矩阵 \(W_e\) 可以表示为 \(W_e = ||S \circ A||_2\)。除了上述的稀疏图,作者还构建了全连通的文本 图,后续试验中发现这两种构建方式互补都可以提升模型的性能。
-
Visual Graph:构建的视觉图表示为 \(G_2 = (V_2,E_2)\),是一个全连通图,节点为提取的 region,同时作者参考 Will3等人的方法,构建极坐标建模图像 region 之间的空间关系,并以 pair-wise 极坐标作为视觉图的边权重构成矩阵 \(W_e\) 。
3. Multimodal Graph Matching
给定了文本图表示 \(G_1 = (V_1, E_1)\) 和视觉图表示 \(G_2= (V_2,E_2)\),目标是匹配 \(G_1\) 和 \(G_2\) 来学习细粒度对应关系,定义文本图中的节点表示矩阵为 \(U_\alpha \in \mathbb{R}^{m\times d}\),视觉图中的节点表示矩阵为 \(V_\beta \in \mathbb{R}^{n\times d}\),其中 \(m,n\) 分别表示包含的节点数量。首先进行 node-level matching 来学习节点级的对应关系,随后进行消息传递聚合图中的邻节点表示进行 structure-level matching 学习短语级的对应关系。
-
Node-level Matching:节点级匹配是一个双向的过程,以在 textual 图上的匹配举例,首先计算 visual 和 textual 节点之间的相似性 \(U_\alpha V_\beta ^T\),并按 visual 轴进行 softmax,此时相似性值度量了 visual 节点与每个 textual 节点的对应性,最终再通过相似性值来聚合所有的 visual 节点表示得到在 textual 图上的节点级匹配表示,这一过程对应:
\[C_{t \rightarrow i}=\operatorname{softmax}_{\beta}\left(\lambda U_{\alpha} V_{\beta}^{T}\right) V_{\beta}\] 注意,按照一些现有的方法,得到 textual 节点对应的聚合 visual 表示 \(C_{t\rightarrow i}\) 后,会直接计算全局 相似性得到一个标量匹配分,但这样做就无法进行后续的向量化消息传递,所以作者将 textual 节点和聚合 visual 表示划分为 \(t\) 个 block,分别计算余弦相似性并拼接为最终的匹配向量:
\[x_i= x_{i1}||x_{i2}||...||x_{it}\] 在 visual 图上的匹配过程是对称的,visual 节点对应的 textual 聚合匹配表示为:
\[C_{i\rightarrow t}=\operatorname{softmax}_{\alpha}\left(\lambda V_{\beta} U_{\alpha}^{T}\right) U_{\alpha}\] -
Structure-level Matching:结构级匹配以节点集匹配向量 \(x\) 作为输入,通过聚合节点的邻域匹配向量完成短语级对应性学习。仍然以 “A brown dog bite a gray dog ear” 为例,”brown” 和 “bite” 作为第一个 “dog” 的邻节点,聚合 “dog” 的邻节点信息即 “brwon”、”bite” 能够帮助模型正确的对应出图片中的对象。
邻域聚合的过程通过 GCN 实现,通过 \(K\) 个卷积核聚合邻域信息:
\[\hat{x}_{i}=\|_{k=1}^{K} \sigma\left(\sum_{j \in N_{i}} W_{e} W_{k} x_{j}+b\right)\] 其中,\(N_{i}\) 为邻居节点集,\(W_e\) 为边权重矩阵,\(W_k,\ b\) 为卷积核的参数,上式同时在 textual 以及 visual 两个维度进行。在得到短语级的匹配向量 \(\hat{x}_{i}\) 后,将所有的短语级匹配向量输入到两层 MLP 中得到最终的全局匹配得分,同样分为 textual 和 visual 两个维度进行:
\[s_{t \rightarrow i}=\frac{1}{n} \sum_{i} W_{s}^{u}\left(\sigma\left(W_{h}^{u} \hat{x}_{i}+b_{h}^{u}\right)\right)+b_{s}^{u} \\ s_{i \rightarrow t}=\frac{1}{m} \sum_{j} W_{s}^{v}\left(\sigma\left(W_{h}^{v} \hat{x}_{j}+b_{h}^{v}\right)\right)+b_{s}^{v}\] 其中,\(W, b\) 为两层 MLP 的参数。最后的全局 text-image 匹配得分为:\(g(G_1,G_2)=s_{t \rightarrow i}+s_{i \rightarrow t}\)
Pixel-BERT: Aligning Image Pixels with Text by Deep Multi-Modal Transformers —预印,University of Science and Technology Beijing & Microsoft Research
Motivation
区别于大部分基于提取图像 region 并对齐文本的方法,提取图像 region 时使用 bounding box 标注会带来一些问题包括信息受损和重叠冗余,如下图,对于 (A) 提取”飞机“后无法判断飞机的状态,对于 (B) 提取”运动员“与”地面“后由于 bbox 存在重叠难以进行特征融合,对于 (C) 提取”长颈鹿“后无法判断其运动状态;除此之外,基于 region 提取的方法表达能力受限于预训练模型如 Faster-RCNN 所能提取的对象类别。因此作者提出直接通过对齐图像的像素与文本以解决上述问题。

Fig. 1. 存在的问题. (Image source: Z Huang et al.)
Method
提出的 Pixel-BERT 模型框架如下图所示,包含视觉特征和文本特征嵌入模块(CNN-based Visual Encoder、Sentence Encoder),跨模态对齐模块(Cross-modality Alignment)并通过 Masked Language Model、Image-Text Matching 任务进行预训练。Pixel-BERT 属于 Single-Stream 类模型,即使用单个 Transformer 结构处理 image 和 text 模态的联合输入。
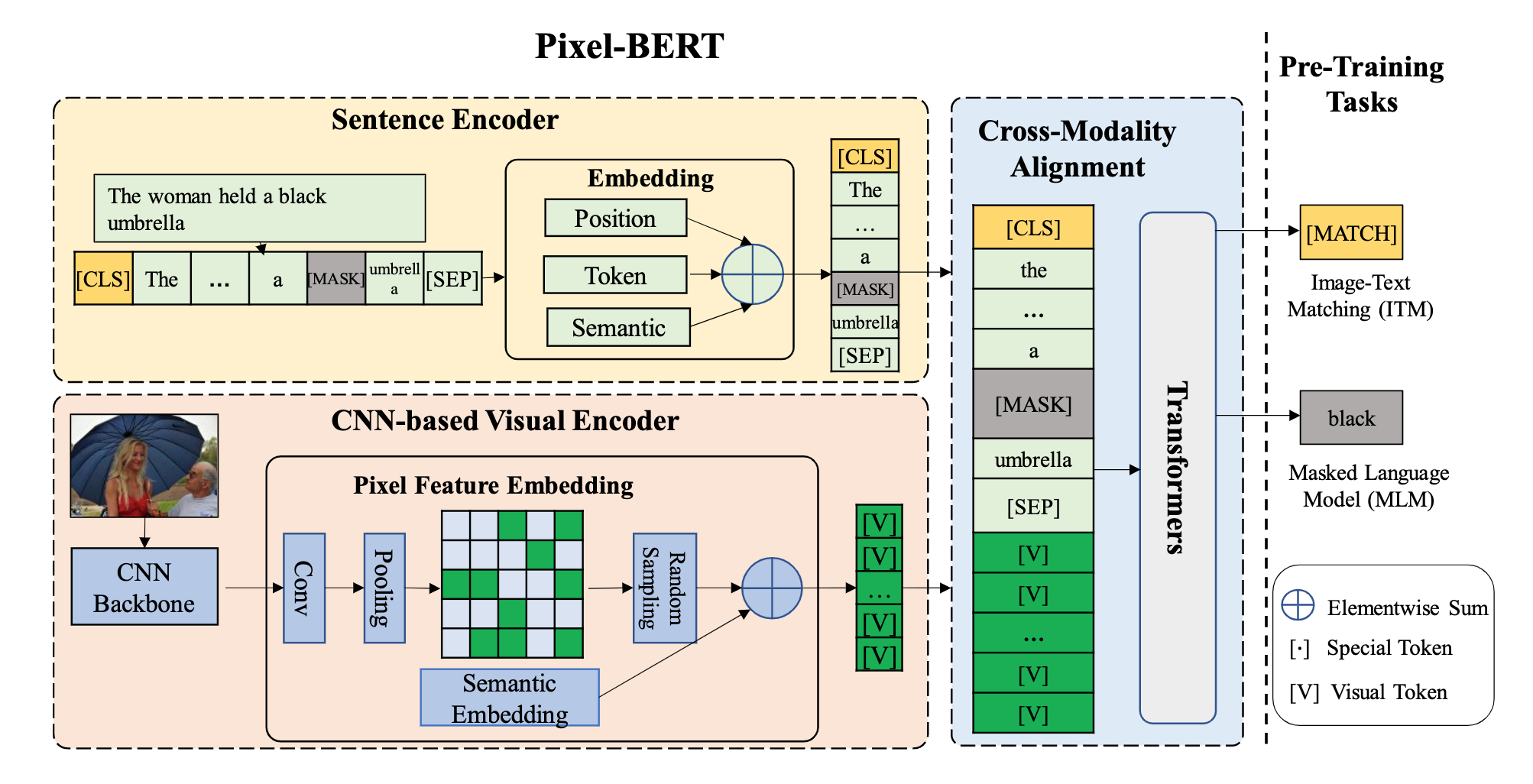
Fig. 2. PixelBERT框架示意图. (Image source: Z Huang et al.)
1. 模型框架
- Sentence Feature Embedding:采用和 BERT 类似的处理方式,输入的文本将被 tokenization 并结合 position embedding,这里忽略了 BERT 中的 segment embedding,最终得到文本表示序列 \(\{\hat{w}_1,\hat{w}_2,...,\hat{w}_n\}\)。
- Image Feature Embedding:首先使用 CNN 的 backbone 网络例如 ResNet-50 提取图像特征并随机采样得到像素级的特征,随后加入 segment embedding 以区别文本表示,最终得到的图像嵌入表示为采样的 \(k\) 个像素点序列 \(\{\hat{v}_1,\hat{v}_2,...,\hat{v}_k\}\)。
-
Cross-Modality Alignment:通过添加 \([\text{CLS}]\)、\([\text{SEP}]\) token 得到最终输入到 Transformer 中的跨模态嵌入表示:
\[\{[\text{CLS}],\hat{w}_1,\hat{w}_2,...,\hat{w}_n,[\text{SEP}],\hat{v}_1,\hat{v}_2,...,\hat{v}_k\}\]注意,Transformer 和提取图像特征的 CNN backbone 是联合训练的。
2. 预训练任务
- Masked Language Modeling:与 BERT 类似,mask 15% 的 textual token,但不同的地方在于,Pixel-BERT 根据 non-mask 的 textual token 以及 visual token 预测这些被 mask 的 textual token。
- Image-Text Matching:以数据集中的 text-image pair 作为正样本,随机负采样的得到负样本,以 \([\text{CLS}]\) 输出作为预测的匹配概率,最终得到交叉熵损失进行训练。
Dense Regression Network for Video Grounding — South China University of Technology & Tsinghua University,CVPR 2020
Motivation
视频定位(Video Grounding)任务的一个难点在于对于一个包含数千帧的视频,仅仅存在一些标注的起始/终止帧可以作为正样本(如下图所示),对于这种不平衡数据,大多数传统方法直接训练一个二分类器,缺乏利用 groundtruth 边界内的帧信息造成结果往往不够好。作者提出,可以使用所有 groundtruth 片段内的帧与起始/终止帧的距离作为密集监督信号来改善最终定位的准确性。
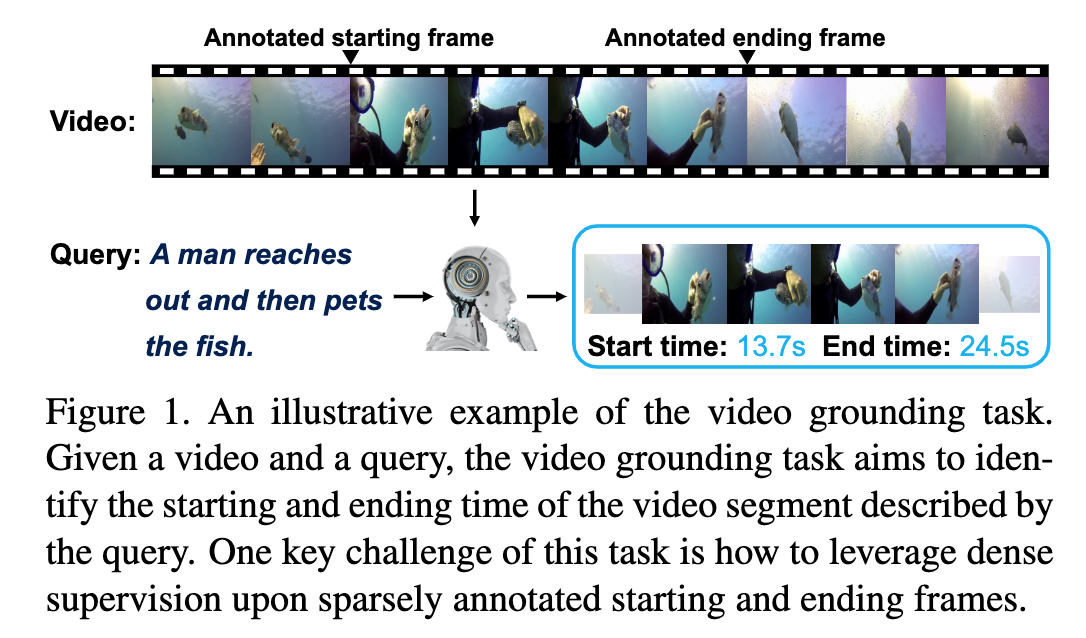
Fig. 1. 正样本不足. (Image source: R Zeng et al.)
Method
作者提出 Dense Regression Ntwork(DRN)网络,DRN 是受 one-stage 目标检测模型 FCOS4 的启发,FCOS 充分利用 groundtruth bounding box 中的所有像素来回归出 bounding box 以训练模型。因此,DRN 采用类似的思想根据 groundtruth 边界内的所有帧来回归预测出 groundtruth 起始/终止边界,这种方式可以更好地从稀疏的标注数据中获取密集的监督信号,即在 groundtruth 边界内的帧都可以视为训练正样本,降低了训练难度。
DRN 网络的示意图如下图所示,给定视频 \(V=\{I_t \in \mathbb{R}^{H \times W \times 3}\}_{t=1}^T\),\(I_t\) 表示 \(t\) 时刻长和宽为 \(H,W\) 的视频帧,同时给定查询文本 \(Q=\{w_n\}_{n=1}^N\),DRN 的目标是定位出与 \(Q\) 相关的视频片段的时序边界 \(\mathbf{b}=(t_s,t_e)\)。DRN 主要包含两大模块,输入的文本和视频首先通过 Video-Query Interaction Module 提取多尺度的特征图,随后每个特征图都将输入到 Grounding Module 得到预测的时序边界。
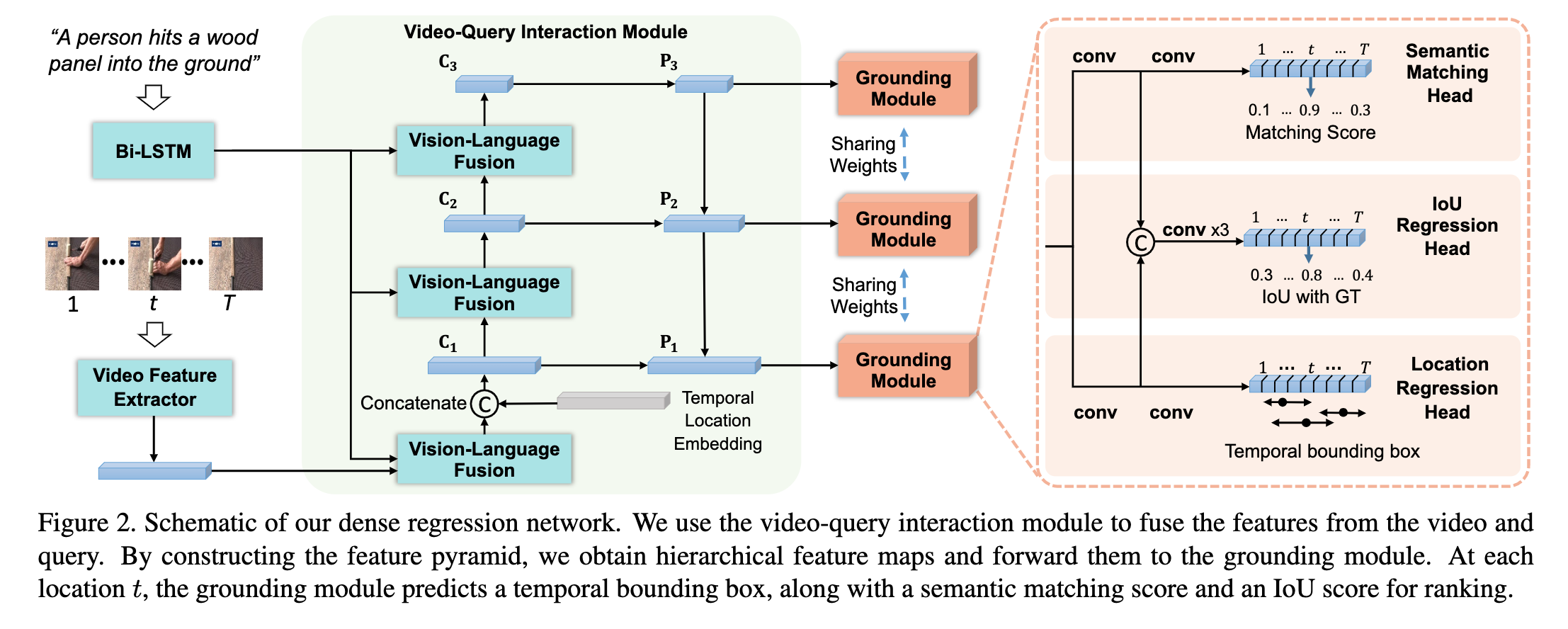
Fig. 1. DRN框架示意图. (Image source: R Zeng et al.)
1. Multi-level video-query interaction module
首先,对于输入的包含 \(T\) 个帧的视频通过 C3D 等模型提取视频特征表示 \(\mathbf{F}\in \mathbb{R}^{T\times c}\),\(c\) 是 channel 维度,对于查询文本 \(Q\) 通过 Bi-LSTM 得到单词表示序列 \(\{\mathbf{h}_n\}_{n=1}^N\),
-
Multi-level Fusion:由于数据集中的标注片段长度跨度很大(最短的只有 2.4s 最长的有 180s)因此作者采用多级融合的策略,对于第 \(i\) 层级,将计算得到一个注意力查询 \(\mathbf{q}_i\):
\[\begin{aligned} \mathbf{q}_{i} &=\sum_{n=1}^{N} \alpha_{i, n} \cdot \mathbf{h}_{n} \\ \alpha_{i, n} &=\operatorname{Softmax}\left(W_{1}\left(\mathbf{h}_{n} \odot\left(W_{2}^{(i)} \operatorname{ReLU}\left(W_{3} g\right)\right)\right)\right) \end{aligned}\] 其中,\(W_1,W_3\) 共享与不同的层级,\(W_2^{(i)}\) 由第 \(i\) 层学习得到,通过与视频特征 \(\mathbf{F}\) 交互得到第 \(i\) 层的 融合结果 \(C_i\),不同层级的融合结果还会采用类似 FPN 的结构,融合不同层级的 \(C_i\) 得到最终输入 到 Grounding Module 的输入 \(\mathbf{P}_i\)。
-
Temporal location embedding:在得到 \(C_i\) 的过程中,还会 concat 视频的时序位置嵌入信息,这样做的好处是当查询中有 “before”、“after” 之类的词汇时,时序信息的融入可以更好地帮助模型学习,对于第 \(t\) 个帧,定义其时序位置嵌入为 \(l_t = \{\frac{t-0.5}{T},\frac{t+0.5}{T},\frac{1}{T}\}\)。
2. Grounding Module
在得到 video-query 融合表示 \(\mathbf{P}\) 之后,需要预测每个帧与查询相关的时序边界,对于预测的边界主要关注两个问题:1)预测得到的边界内视频内容是否和查询语义相关?2)预测的边界位置是否和 groundtruth 边界位置匹配?作者用三个子模块来完成目标,Location regression head \(M_{l o c}\) 负责为每一个帧预测其与查询相关的视频片段边界;Semantic matching head \(M_{match}\) 负责找出与查询最相关的预测片段;IoU regression head \(M_{iou}\) 负责判断预测得到的边界的质量,度量与 groundtruth 边界的 IoU 差异。
-
Location regression head:对于 \(\mathbf{P}\) 中的某个帧 \(t\) ,如果其落在 groundtruth 边界内,则使用两个 1Dconv 层预测其与 groundtruth 起始/终止位置的距离得到预测的回归向量 \(\hat{d}_t=(\hat{d}_{t,s},\hat{d}_{t,e})\):
\[\hat{d}_{t,s}=t-t_s,\ \ \ \ \hat{d}_{t,e}=t_e-t\] \(t_s,t_e\) 表示 groundtruth 边界位置,由于 \(t\) 落在 groundtruth 内,因此 \(d_{t,s},d_{t,e}\) 均为正实值,而对 于没有落在 groundtruth 边界内的帧,则不会用于训练,最终得到的预测边界为:
\[\begin{aligned} \left\{\hat{\mathbf{b}}_{t}\right\}_{t=1}^{T} &=\left\{\left(t-\hat{d}_{t, s}, t+\hat{d}_{t, e}\right)\right\}_{t=1}^{T} \\ \left\{\left(\hat{d}_{t, s}, \hat{d}_{t, e}\right)\right\}_{t=1}^{T} &=M_{l o c}\left(G\left(\left\{I_{t}\right\}_{t=1}^{T},\left\{w_{n}\right\}_{n=1}^{N}\right)\right) \end{aligned}\] 这部分的损失函数如下:
\[L_{l o c}=\frac{1}{N_{p o s}} \sum_{t=1}^{T} \mathbb{1}_{g t}^{t} L_{1}\left(\boldsymbol{d}_{t}, \hat{\boldsymbol{d}}_{t}\right)\] 其中 \(N_{pos}\) 表示正样本的数量,\(\mathbb{1}_{g t}^{t}\) 表示指示函数(indicator function)表示如果帧 \(t\) 落在 groundtruth 内则为 1 否则为 0,\(L_1\) 则表示 IoU 回归损失函数。
-
Semantic matching head:通过 \(M_{l o c}\) 得到 \(\hat{\mathbf{b}}_{t}\) 后,再通过同样由两个 1Dconv 层构成的 \(M_{match}\) 预测其语义匹配得分 \(\hat{m}_t\) 以用于挑选最接近查询的预测边界,对于 groundtruth 内的帧,设置其标签 \(m_t=1\),而 groundtruth 外的帧标签则为 0,此部分的损失函数如下:
\[L_{m a t c h}=\frac{1}{N_{p o s}} \sum_{t=1}^{T} L_{2}\left(m_{t}, \hat{m}_{t}\right)\]其中,\(L_2\) 为 focal loss。
-
IoU regression head:\(\hat{m}_t\) 度量了预测边界内的视频内容与查询的相关度,为了进一步度量预测边界与 groundtruth 边界的定位准确度,通过预测 \(\boldsymbol{\hat{b}}_t\) 的 IoU 值 \(\hat{u}_t\) 来实现定位准确度度量。这里引入 FCOS 中的 “centerness” 技巧,其假设位于目标中心的像素点有更高的概率预测出准确度更高的边界,并抑制其他位置的预测结果。\(M_{iou}\) 采用三层卷积层实现,其输入为 \(M_{loc}\) 和 \(M_{match}\) 的第一个 1Dconv 层的 concat 结果。这部分的损失函数为:
\[L_{i o u}=\sum_{t=1}^{T} L_{3}\left(u_{t}, \hat{u}_{t}\right)\] 其中,\(L_3\) 为 Smooth-L1 损失,注意这里 \(u_t\) 是预测得到的边界 \(\boldsymbol{\hat{b}}_t\) 与 groundtruth 边界的 IoU, 是在训练过程中实时计算出来的。
Reference
-
Peng Shi and Jimmy Lin. Simple bert models for relation extraction and semantic role labeling. ↩
-
Kuang-Huei Lee, Xi Chen, Gang Hua, etc. Stacked cross attention for image-text matching. ↩
-
Will Norcliffe-Brown, Stathis Vafeias, and Sarah Parisot. Learning conditioned graph structures for interpretable visual question answering ↩
-
Zhi Tian, Chunhua Shen, Hao Chen, et al. Fcos:Fully convolutional one-stage object detection. ↩